Du kennst das Gefühl. Dein Linux-Server reagiert plötzlich träge, Dienste stürzen ohne Vorwarnung ab oder Log-Dateien lassen sich nicht mehr schreiben. Meistens liegt die Ursache begraben unter Bergen von Datenmüll, verwaisten Paketen oder explodierenden Datenbanken. Wenn du Check Disc Space In Linux verstehen willst, reicht es nicht, nur einen Befehl blind in das Terminal zu hämmern. Du musst begreifen, wie Linux mit Dateisystemen jongliert und wo sich die Speicherfresser verstecken. Es geht hier nicht um graue Theorie. Es geht darum, dass dein System stabil läuft, egal ob es ein kleiner Raspberry Pi im Wohnzimmer oder eine riesige Instanz in der Cloud ist.
Warum die Standardwerkzeuge oft missverstanden werden
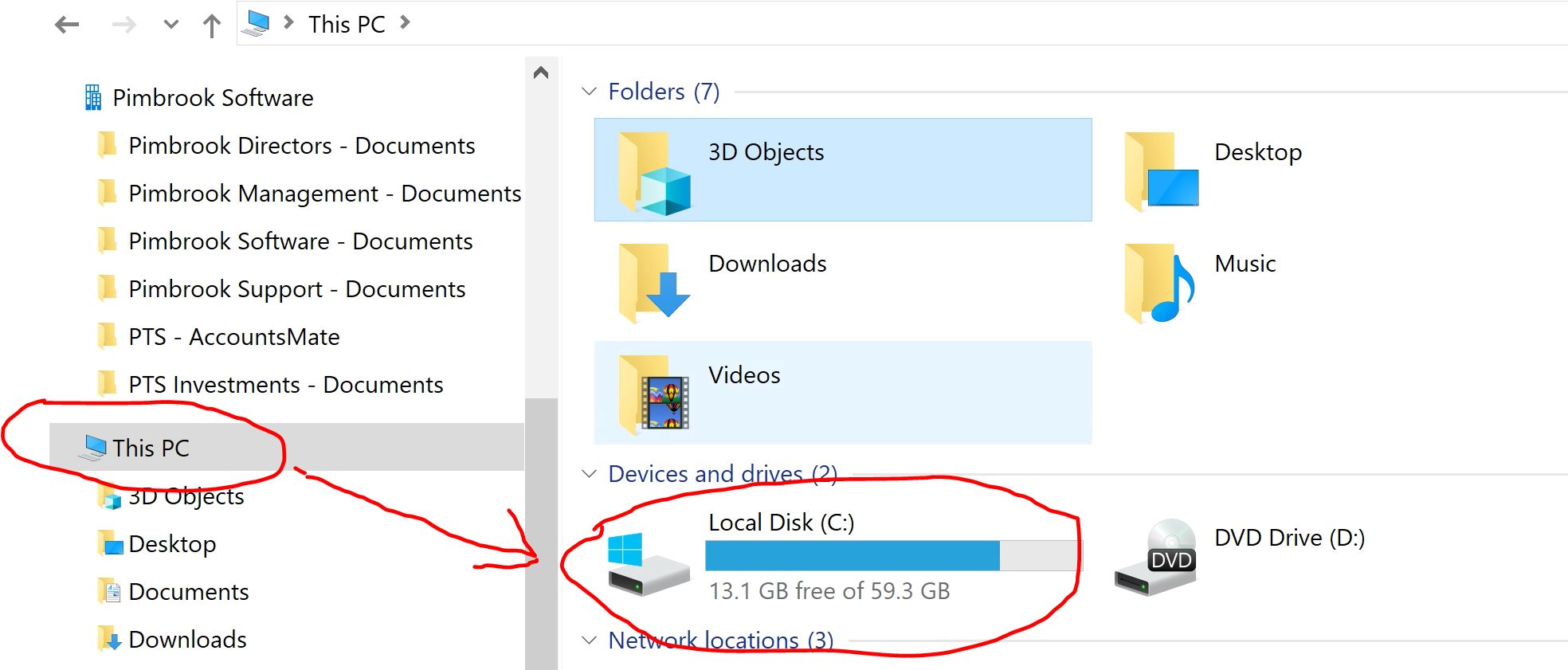
Wer zum ersten Mal vor einer Linux-Konsole sitzt, greift meist instinktiv zum Befehl df. Das ist ein solider Anfang. Die Abkürzung steht für "disk free" und zeigt dir die Belegung deiner montierten Dateisysteme an. Aber hier fangen die Probleme schon an. Ohne die richtigen Parameter wirft dir das System kryptische 1K-Block-Zahlen entgegen, mit denen kein Mensch spontan etwas anfangen kann.
Ich nutze fast immer df -h. Das "h" steht für "human-readable". Plötzlich siehst du Gigabyte und Megabyte statt unendlicher Zahlenreihen. Doch Vorsicht ist geboten. Ein häufiger Fehler besteht darin, nur auf die Prozentanzeige zu schauen. Linux-Dateisysteme wie ext4 reservieren standardmäßig etwa fünf Prozent des Speichers für den Benutzer root. Wenn deine Anzeige also 95 Prozent meldet, kann es für einen normalen Benutzer schon so wirken, als wäre die Platte komplett voll. Das System schützt sich damit selbst, damit kritische Dienste auch dann noch Logs schreiben können, wenn du deine Home-Partition mit Urlaubsvideos zugemüllt hast.
Den Durchblick bei Mountpoints behalten
Ein Linux-System ist kein Windows-Rechner mit Laufwerk C oder D. Alles ist ein Baum. Wenn du die Speicherbelegung prüfst, musst du wissen, wo welche Festplatte eingehängt ist. Die Ausgabe von df zeigt dir in der linken Spalte das Gerät, zum Beispiel /dev/sda1, und rechts den Einhängepunkt wie /var oder /home.
Besonders tückisch sind temporäre Dateisysteme wie tmpfs. Diese belegen keinen Platz auf deiner echten SSD, sondern liegen im Arbeitsspeicher. Wenn du also siehst, dass /run fast voll ist, hilft es nichts, alte Dateien zu löschen. Du musst schauen, welcher Prozess den RAM auffrisst. Das ist ein feiner, aber wichtiger Unterschied in der täglichen Administration.
Strategien für Check Disc Space In Linux auf der Kommandozeile
Wenn du weißt, dass der Platz knapp ist, musst du den Schuldigen finden. Hier kommt du ins Spiel, kurz für "disk usage". Während df dir das große Ganze zeigt, geht du in die Details der Verzeichnisse. Wer ohne Plan du / eingibt, wird von einer Textlawine erschlagen. Das ist Zeitverschwendung.
Besser ist die Kombination du -sh * in dem Verzeichnis, das du verdächtigst. Das zeigt dir die Größe aller Ordner in der aktuellen Ebene an. Ich habe es oft erlebt, dass Administratoren stundenlang nach Fehlern in der Datenbank suchen, nur um dann festzustellen, dass das Verzeichnis /var/log durch einen Amok laufenden Dienst auf 50 GB angewachsen ist. Ein Blick in die Dokumentation von Debian hilft oft, um zu verstehen, wie Standardpfade für Protokolle definiert sind.
Das Problem mit gelöschten aber offenen Dateien
Das ist ein Klassiker, der jeden Linux-Admin mindestens einmal in den Wahnsinn treibt. Du löschst eine riesige Log-Datei mit rm. Du prüfst mit df, aber der freie Speicherplatz erhöht sich nicht. Warum? In der Welt von Linux wird der Speicherplatz erst dann wirklich freigegeben, wenn kein Prozess mehr auf die Datei zugreift. Wenn der Webserver die Datei noch offen hält, bleibt der Platz belegt, obwohl die Datei im Verzeichnis nicht mehr sichtbar ist.
In so einem Fall hilft der Befehl lsof | grep deleted. Er listet dir alle Dateien auf, die zwar gelöscht, aber noch von Programmen blockiert sind. Ein Neustart des betroffenen Dienstes löst das Problem sofort. Das ist ein Praxistipp, den du in keinem einfachen Tutorial findest, der dir aber bei der Fehlersuche extrem viel Zeit spart.
Inodes als versteckte Platzfresser
Es gibt eine Situation, in der dein System meldet, dass kein Speicherplatz mehr vorhanden ist, obwohl df -h noch viele Gigabyte als frei anzeigt. Das passiert, wenn dir die Inodes ausgehen. Jede Datei und jedes Verzeichnis benötigt einen Inode. Wenn du Millionen von winzigen Dateien hast — etwa Session-Files eines Webservers — kann die Inode-Tabelle voll sein.
Mit df -i kannst du diesen speziellen Status prüfen. Ich hatte diesen Fall einmal bei einem Mailserver, der Millionen kleiner Spam-Mails in der Warteschlange hängen hatte. Der Speicherplatz war da, aber das System konnte keine neue Datei mehr anlegen, weil kein "Index-Eintrag" mehr frei war. Hier hilft nur radikales Löschen der kleinen Dateien.
Werkzeuge für mehr Komfort und Übersicht
Manchmal will man sich nicht durch endlose Textwüsten kämpfen. Es gibt Tools, die die Arbeit im Terminal grafisch aufbereiten, ohne dass du eine komplette Desktop-Umgebung brauchst. Mein Favorit ist ncdu. Das steht für "NCurses Disk Usage".
Du installierst es meist einfach über den Paketmanager deiner Distribution, etwa mit sudo apt install ncdu unter Ubuntu oder Debian. Wenn du es startest, scannt es das Verzeichnis und präsentiert dir eine sortierte Liste. Du kannst mit den Pfeiltasten durch die Ordner navigieren und siehst sofort, wo die dicken Brocken liegen. Es ist schnell, effizient und intuitiv.
Automatisierung der Überwachung
Niemand hat Lust, jeden Morgen manuell zu prüfen, wie viel Platz noch da ist. Das muss automatisch passieren. Ein simpler Cronjob kann dir eine E-Mail schicken, wenn die Partition zu mehr als 90 Prozent gefüllt ist. Profis nutzen dafür Monitoring-Lösungen wie Prometheus oder Checkmk. Diese Tools sammeln Daten über lange Zeiträume.
Das ist nützlich, um Trends zu erkennen. Wenn dein Speicherplatz linear wächst, weißt du, dass du in drei Monaten eine größere Festplatte brauchst. Wenn er sprunghaft ansteigt, stimmt etwas mit deiner Applikation nicht. Für Unternehmen in Deutschland ist Datensicherheit und Verfügbarkeit ein kritisches Thema, weshalb solche Vorhersagen oft Teil von Compliance-Richtlinien sind. Informationen zu Best Practices in der IT-Sicherheit findest du auch beim Bundesamt für Sicherheit in der Informationstechnik.
Die Rolle von Docker und virtuellen Dateisystemen
In der modernen IT nutzen wir ständig Container. Docker ist wunderbar, aber es ist ein Speicherfresser vor dem Herrn. Alte Images, ungenutzte Volumes und gestoppte Container sammeln sich im Verzeichnis /var/lib/docker an. Wenn du dort nicht regelmäßig aufräumst, ist die Platte schneller voll, als du "Microservices" sagen kannst.
Ein docker system prune wirkt hier oft Wunder. Es löscht alles, was nicht aktiv verwendet wird. Aber Vorsicht: Damit verschwinden auch ungenutzte Netzwerke und der Build-Cache. Wer präziser vorgehen will, muss die einzelnen Bereiche wie Images und Volumes separat prüfen. Linux macht es uns hier nicht immer leicht, weil Docker viele Layer übereinander schichtet, was die Berechnung des tatsächlichen Platzverbrauchs erschwert.
Partitionierung und LVM
Früher war eine volle Partition eine Katastrophe. Man musste das System im Rettungsmodus booten und mühsam die Partitionsgrenzen verschieben. Heute nutzen fast alle professionellen Installationen den Logical Volume Manager (LVM). LVM erlaubt es dir, Speicherplatz im laufenden Betrieb hinzuzufügen.
Stell dir vor, deine /var-Partition läuft voll. Mit LVM kannst du einfach eine neue Festplatte ins System stecken, sie zur Volume Group hinzufügen und die Partition vergrößern. Das Dateisystem, zum Beispiel XFS oder ext4, lässt sich danach mit einem einfachen Befehl wie resize2fs oder xfs_growfs an die neue Größe anpassen. Das passiert alles, während deine Webseite oder deine Datenbank weiterläuft. Das ist Flexibilität, wie sie in Rechenzentren Standard ist.
Check Disc Space In Linux für Fortgeschrittene
Wenn du wirklich wissen willst, was unter der Haube passiert, musst du dich mit Journaling-Dateisystemen beschäftigen. Das Journal verbraucht selbst Platz. Bei Dateisystemen wie Btrfs oder ZFS kommen noch Snapshots hinzu. Ein Snapshot ist eine Kopie des Zustands zu einem bestimmten Zeitpunkt. Das Geniale: Er verbraucht anfangs fast keinen Platz.
Erst wenn sich Daten im Original ändern, fängt der Snapshot an zu wachsen. Wenn du viele Snapshots behältst und gleichzeitig große Datenbank-Updates fährst, kann dein Speicherplatz schlagartig verschwinden. Hier zeigt df oft falsche Werte an, weil es die komplexe Struktur von ZFS-Pools nicht versteht. In solchen Fällen musst du die spezifischen Werkzeuge des Dateisystems nutzen, etwa zfs list.
Die Falle mit den Sparse Files
Ein weiteres Phänomen sind sogenannte Sparse Files. Das sind Dateien, die vorgeben, sehr groß zu sein, aber nur den Platz belegen, der tatsächlich mit Daten gefüllt ist. Virtuelle Festplatten für QEMU oder VirtualBox sind oft so konzipiert. Wenn du eine 100 GB große virtuelle Platte anlegst, aber nur 2 GB Daten darin speicherst, belegt sie auf deinem Host-System auch nur 2 GB.
Wenn du diese Datei jedoch mit einem Tool kopierst, das Sparse Files nicht unterstützt, wird die Datei plötzlich auf die vollen 100 GB aufgebläht. Das kann dein Zielmedium sofort sprengen. Beim Prüfen des Speicherplatzes hilft hier der Befehl ls -lsh, der sowohl die scheinbare Größe als auch den tatsächlich belegten Platz auf der Festplatte anzeigt.
Praktische Schritte zur dauerhaften Speicherhygiene
Es bringt nichts, einmal im Jahr aufzuräumen. Du brauchst ein System. Der erste Schritt ist die Konfiguration von logrotate. Dieses Werkzeug sorgt dafür, dass alte Log-Dateien komprimiert und nach einer gewissen Zeit gelöscht werden. Eine schlecht konfigurierte logrotate.conf ist die häufigste Ursache für volle Festplatten auf Webservern.
Zweitens solltest du den Paket-Cache deines Systems im Auge behalten. Unter Ubuntu sammeln sich in /var/cache/apt/archives alle jemals heruntergeladenen Pakete an. Ein gelegentliches sudo apt-get clean befreit dich von diesem Ballast. Das sind oft mehrere Gigabyte, die einfach nur herumliegen.
Drittens ist die Überwachung von Benutzerverzeichnissen wichtig. Wenn du ein Mehrbenutzersystem betreibst, können Quotas helfen. Damit setzt du jedem User ein Limit. Wenn die Grenze erreicht ist, kann der Nutzer keine weiteren Dateien speichern. Das klingt hart, verhindert aber, dass ein einzelner Nutzer das gesamte System lahmlegt.
Lokale Suche nach großen Dateien
Manchmal suchst du die Nadel im Heuhaufen. Du weißt, irgendwo ist eine Datei, die 5 GB groß ist, aber du hast keine Ahnung, wo. Der Befehl find ist dein bester Freund. Mit find / -type f -size +1G suchst du im gesamten System nach Dateien, die größer als ein Gigabyte sind.
Ich kombiniere das oft mit exec ls -lh, um direkt die Details zu sehen. Das dauert zwar einen Moment, weil das System jede Verzeichnisstruktur durchkämmen muss, aber es ist die sicherste Methode, um vergessene ISO-Images oder alte Datenbank-Dumps zu finden. Oft sind es genau diese manuellen Backups, die man "mal eben schnell" gemacht und dann vergessen hat.
Die Bedeutung von Cloud-Speicher und Objektspeicher
In Zeiten von AWS, Azure und Hetzner Cloud verschiebt sich die Problematik etwas. Speicherplatz lässt sich hier per Mausklick erweitern. Aber das kostet Geld. Wer Check Disc Space In Linux vernachlässigt, zahlt am Ende des Monats eine höhere Rechnung für Speicher, den er eigentlich gar nicht braucht.
Objektspeicher wie S3 ist eine gute Alternative für große Datenmengen. Statt deine lokale SSD mit Nutzer-Uploads zu füllen, schiebst du die Daten in den Objektspeicher. Das hält dein System schlank und macht Backups deutlich einfacher. Dennoch musst du auch dort die Belegung im Auge behalten, da auch Cloud-Anbieter keine unbegrenzten Geschenke machen.
Dateisystem-Checks und Reparaturen
Manchmal ist der Speicherplatz gar nicht belegt, sondern das Dateisystem ist beschädigt. Fehlerhafte Metadaten können dazu führen, dass der freie Platz falsch berechnet wird. In so einem Fall hilft ein Dateisystemcheck mit fsck. Das solltest du niemals auf einem gemounteten System tun. Du musst von einem Live-System booten oder die Partition im Nur-Lese-Modus prüfen.
Moderne Dateisysteme wie XFS sind sehr robust und reparieren viele Fehler im Hintergrund, aber eine physisch sterbende Festplatte kündigt sich oft durch seltsame Speicherplatzanzeigen oder E/A-Fehler an. Ein Blick in die SMART-Werte deiner Platte mit smartctl gibt dir Gewissheit über den Gesundheitszustand deiner Hardware. Das Tooling der Smartmontools ist hier der Industriestandard.
Zusammenfassung der wichtigsten Befehle
Du hast jetzt einen tiefen Einblick in die Mechanismen erhalten. Hier sind die Werkzeuge, die du ab jetzt regelmäßig nutzen solltest:
- Nutze
df -hfür den schnellen Überblick über alle Partitionen. - Verwende
du -shin spezifischen Ordnern, um Speicherfresser zu identifizieren. - Installiere
ncdu, wenn du eine komfortable, interaktive Ansicht im Terminal bevorzugst. - Prüfe mit
df -i, ob dir die Inodes ausgehen, fallsdf -hnoch Platz anzeigt. - Nutze
find / -size +500M, um gezielt nach großen Dateien zu suchen. - Leere regelmäßig den Paketmanager-Cache mit
apt cleanoder ähnlichen Befehlen deiner Distribution. - Behalte gelöschte, aber noch offene Dateien mit
lsofim Blick.
Diese Schritte sind keine einmalige Aktion. Speicherverwaltung ist ein kontinuierlicher Prozess. Wenn du diese Befehle beherrschst und verstehst, was sie dir sagen, wirst du nie wieder von einer vollen Festplatte überrascht. Es geht darum, proaktiv zu handeln, bevor der Server den Dienst quittiert. Ein gut gepflegtes System ist die Basis für jede professionelle IT-Infrastruktur. Fang heute damit an, deine /var/log Verzeichnisse zu prüfen und alte Docker-Images zu löschen. Dein System wird es dir mit Stabilität und Geschwindigkeit danken.



