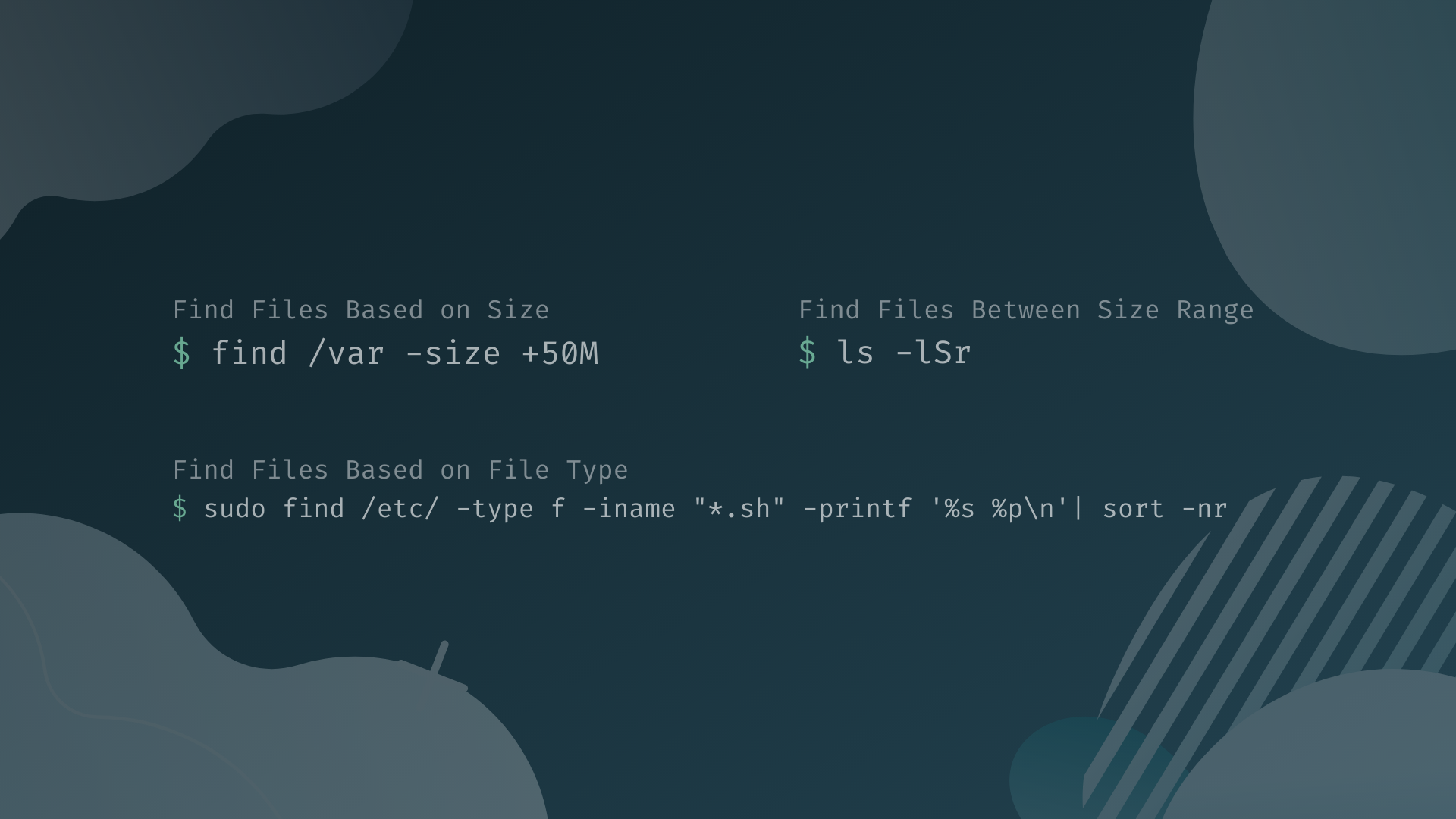
Stellen Sie sich vor, es ist drei Uhr morgens. Ihr Monitoring-System schlägt Alarm, weil der Datenbankserver keine Schreibvorgänge mehr zulässt. Die Partition ist zu 100 Prozent belegt. In Panik tippen Sie einen der ersten Befehle ein, die Sie online unter dem Schlagwort Find The Largest Files In Linux gefunden haben, und lassen ihn über das gesamte Wurzelverzeichnis laufen. Während das System minutenlang versucht, Millionen von Metadaten einzulesen, wird die Last auf der Festplatte so hoch, dass selbst Ihre SSH-Verbindung einfriert. Ich habe Administratoren gesehen, die in dieser Situation den Server hart neu gestartet haben, nur um danach festzustellen, dass das Dateisystem beschädigt war. Ein simpler Platzmangel wurde durch eine unüberlegte Suche nach großen Dateien in eine Katastrophe verwandelt, die Stunden an Wiederherstellungszeit kostete.
Der Fehler der globalen Suche ohne Mountpoint-Begrenzung
Einer der häufigsten Fehler, den ich in über zehn Jahren Linux-Administration erlebt habe, ist die mangelnde Unterscheidung zwischen lokalen Dateisystemen und Netzwerkfreigaben. Wenn Sie den Befehl absetzen, um im gesamten System nach Platzfressern zu suchen, ahnen Sie oft nicht, dass Ihr Server vielleicht ein riesiges NFS-Laufwerk oder ein Backup-Archiv über das Netzwerk eingebunden hat.
Das Ergebnis? Der Befehl versucht, Terabytes an Daten über das Netzwerk zu scannen. Das kostet nicht nur Zeit, sondern verstopft die Bandbreite für alle anderen Dienste. In einem Fall, den ich begleitete, legte ein Junior-Admin das gesamte Firmennetzwerk lahm, weil er versuchte, auf einem kleinen Webserver die größten Dateien zu finden, während gleichzeitig die wöchentliche Sicherung auf ein gemountetes Storage-System lief.
Die Lösung ist simpel, aber wird oft vergessen: Nutzen Sie Parameter, die das Tool anweisen, auf dem aktuellen Dateisystem zu bleiben. Wenn Sie wissen, dass /var voll ist, dann suchen Sie nur dort. Linux bietet Mechanismen, um Verzeichnisgrenzen zu respektieren. Wer das ignoriert, spielt russisches Roulette mit der Systemperformance. Es geht darum, gezielt vorzugehen, statt mit der Schrotflinte auf alles zu schießen, was wie ein Verzeichnis aussieht.
Find The Largest Files In Linux und die Falle der gelöschten Dateihandles
Hier ist ein Szenario, das fast jeden Profi schon einmal erwischt hat: Die Festplatte ist voll, Sie finden mit einem Tool eine 50 GB große Log-Datei und löschen sie mit rm. Sie atmen auf, prüfen den Speicherplatz mit df -h – und stellen fest, dass sich absolut nichts geändert hat. Der Platz ist immer noch belegt.
Warum passiert das? Unter Linux wird der Speicherplatz einer Datei erst dann freigegeben, wenn kein Prozess mehr auf sie zugreift. Wenn ein Dienst wie Nginx oder eine Java-Anwendung diese Log-Datei noch offen hält, bleibt der Platz reserviert, obwohl die Datei im Verzeichnisbaum nicht mehr existiert. In dieser Situation nach der Suche Find The Largest Files In Linux einfach nur die Löschtaste zu drücken, ist wirkungslos.
Anstatt die Datei zu löschen, sollten Sie sie leeren. Ein einfaches Umleiten von „Nichts“ in die Datei sorgt dafür, dass der Dateizeiger erhalten bleibt, der Inhalt aber sofort verschwindet und der Platz im Dateisystem wieder verfügbar ist. Ich habe erlebt, wie Admins ganze Server rebootet haben, nur um diese "Phantom-Dateien" loszuwerden, was völlig unnötig war. Ein kurzes Prüfen der offenen Dateihandles hätte gereicht. Es ist der Unterschied zwischen jemandem, der nur Tutorials liest, und jemandem, der versteht, wie der Kernel mit Daten umgeht.
Das Problem mit versteckten Filesystemen
Ein weiterer Punkt, der oft übersehen wird, sind temporäre Dateisysteme oder Overlays in Docker-Umgebungen. Wer hier versucht, manuell aufzuräumen, richtet oft mehr Schaden an als Nutzen. In modernen Infrastrukturen liegen die großen Datenmengen oft in Layern, die man nicht einfach mit Standardwerkzeugen anfasst. Wer hier blind löscht, riskiert instabile Container, die beim nächsten Neustart nicht mehr hochfahren.
Warum Sortieren nach Dateigröße oft die falsche Metrik ist
Die meisten Menschen suchen nach der einen riesigen Datei. Die Realität in der Produktion sieht meistens anders aus. Es ist selten die eine 100 GB Datei, die das System sprengt. Viel öfter sind es Millionen von winzigen 4 KB Dateien, die die Inodes Ihres Dateisystems auffressen.
Einmal rief mich ein Kunde an, dessen Server meldete, der Speicherplatz sei voll. Ein Blick auf die Kapazität zeigte jedoch, dass noch 40 Prozent frei waren. Das Problem? Ein fehlkonfigurierter Mail-Server hatte Millionen kleiner Dateien in einer Warteschlange abgelegt. Jede Datei belegte einen Inode, und diese waren schlichtweg aufgebraucht. Wenn Sie in so einem Moment nur nach der Dateigröße suchen, finden Sie nichts Ungewöhnliches.
Ein praktischer Vorher/Nachher-Vergleich verdeutlicht das Problem:
Ein Administrator, der nur nach Größe sucht (Vorher), sieht eine Liste von Systembibliotheken und Datenbankfiles, die alle ihre normale Größe haben. Er verbringt zwei Stunden damit, Logs zu rotieren, gewinnt aber nur ein paar Megabyte zurück. Die Fehlermeldung bleibt.
Ein erfahrener Praktiker (Nachher) schaut sich die Inode-Belegung an. Er erkennt sofort, dass ein Verzeichnis unter /var/spool komplett überlaufen ist. Er löscht die Millionen kleinen Dateien mit einem gezielten Skript, das nicht an den Argumentgrenzen der Shell scheitert, und behebt das Problem innerhalb von fünf Minuten.
Der Fokus auf die reine Dateigröße ist eine Anfängerfalle. Sie müssen wissen, ob Sie ein Volumenproblem oder ein Metadatenproblem haben. Wer das verwechselt, verliert Zeit und Nerven.
Die Gefahr von rekursiven Suchen in Live-Datenbanken
Ein besonders schmerzhafter Fehler passiert, wenn man Suchen in Verzeichnissen startet, in denen Datenbanken ihre Rohdaten ablegen. Manche Tools, die zur Kategorie Find The Largest Files In Linux gehören, greifen sehr aggressiv auf die Festplatte zu. Wenn Sie das auf einem System machen, das ohnehin schon unter hoher Last steht, kann die zusätzliche I/O-Last die Datenbank zum Absturz bringen.
Ich erinnere mich an einen Vorfall bei einem E-Commerce-Anbieter während eines Sales-Events. Der Server war langsam, und ein Techniker wollte Platz schaffen. Seine Suche nach großen Dateien verursachte so viele Lesezugriffe auf die SSDs, dass die Latenz der Datenbank über den kritischen Schwellenwert stieg. Die Webseite war für 15 Minuten weg – ein Schaden von mehreren zehntausend Euro.
Man darf niemals vergessen, dass jeder Suchbefehl Ressourcen verbraucht. Auf einem ausgelasteten System nutzt man Tools, die die I/O-Priorität senken. So stellt man sicher, dass die Suche den regulären Betrieb nicht stört. Wer einfach nur einen Befehl aus einem Forum kopiert, ohne die Last im Auge zu behalten, handelt fahrlässig. Es ist eben kein Laborsystem, sondern eine lebende Umgebung.
Pseudolösungen durch automatisierte Cleanup-Skripte
Oft versuchen Firmen, das Problem durch Cronjobs zu lösen, die regelmäßig „alte“ oder „große“ Dateien löschen. Das klingt auf dem Papier gut, ist aber in der Praxis eine Zeitbombe. Ich habe gesehen, wie solche Skripte plötzlich wichtige Socket-Dateien oder Locks gelöscht haben, nur weil diese seit zwei Tagen nicht mehr aktualisiert wurden oder eine bestimmte Größe überschritten hatten.
Ein solcher Fall betraf ein Backup-Skript, das seine eigenen temporären Dateien erzeugte. Das Cleanup-Skript hielt diese für Müll und löschte sie mitten im Prozess. Das Ergebnis waren korrupte Backups, was erst Monate später auffiel, als man eines der Backups wirklich brauchte.
Automatisierung ist kein Ersatz für eine vernünftige Monitoring-Strategie. Statt blind zu löschen, sollte man lieber die Ursache für das Datenwachstum finden. Warum wächst dieses Log so schnell? Warum räumt die Applikation ihren temporären Kram nicht auf? Wer nur die Symptome bekämpft, wird diesen Kampf auf Dauer verlieren.
Der Realitätscheck: Was wirklich funktioniert
Um in der Linux-Administration wirklich Erfolg zu haben, müssen Sie sich von der Vorstellung verabschieden, dass es den einen „magischen Befehl“ gibt. Die Realität ist harte Arbeit an der Basis. Sie müssen Ihre Dateisystemhierarchie kennen wie Ihre Westentasche. Sie müssen wissen, welcher Dienst welche Daten wohin schreibt.
Erfolgreiche Administratoren nutzen Monitoring-Tools wie Prometheus oder Zabbix, um Trends zu erkennen, bevor die Platte voll ist. Wenn Sie erst suchen müssen, wenn der Server schon steht, haben Sie eigentlich schon verloren. Es braucht eine proaktive Herangehensweise. Das bedeutet:
- Quotas einrichten, damit ein einzelner Nutzer oder Dienst nicht das ganze System lahmlegen kann.
- Separate Partitionen für
/var,/homeund/tmpverwenden, um die Root-Partition zu schützen. - Log-Rotation korrekt konfigurieren und auch wirklich prüfen, ob sie funktioniert.
Es gibt keine Abkürzung. Wenn Sie glauben, Sie könnten mit ein paar kopierten Befehlen aus dem Internet ein komplexes System stabil halten, liegen Sie falsch. Linux verzeiht vieles, aber Ignoranz gegenüber den Grundlagen des Speichermanagements gehört nicht dazu. Es ist nun mal so: Ein guter Admin ist derjenige, der den Befehl zum Suchen nach großen Dateien fast nie braucht, weil er das System so gebaut hat, dass es gar nicht erst zu diesem Engpass kommt. Alles andere ist nur Krisenmanagement nach dem Ausbruch des Feuers. Wer das versteht, spart sich die schlaflosen Nächte und seinem Arbeitgeber viel Geld. Es ist ein Handwerk, keine Magie. Und wie bei jedem Handwerk kommt die Meisterschaft durch die Narben, die man aus Fehlern der Vergangenheit davongetragen hat. Bleiben Sie wachsam, hinterfragen Sie jeden Befehl und vertrauen Sie niemals blind einer Ausgabe, die Sie nicht selbst interpretieren können.



