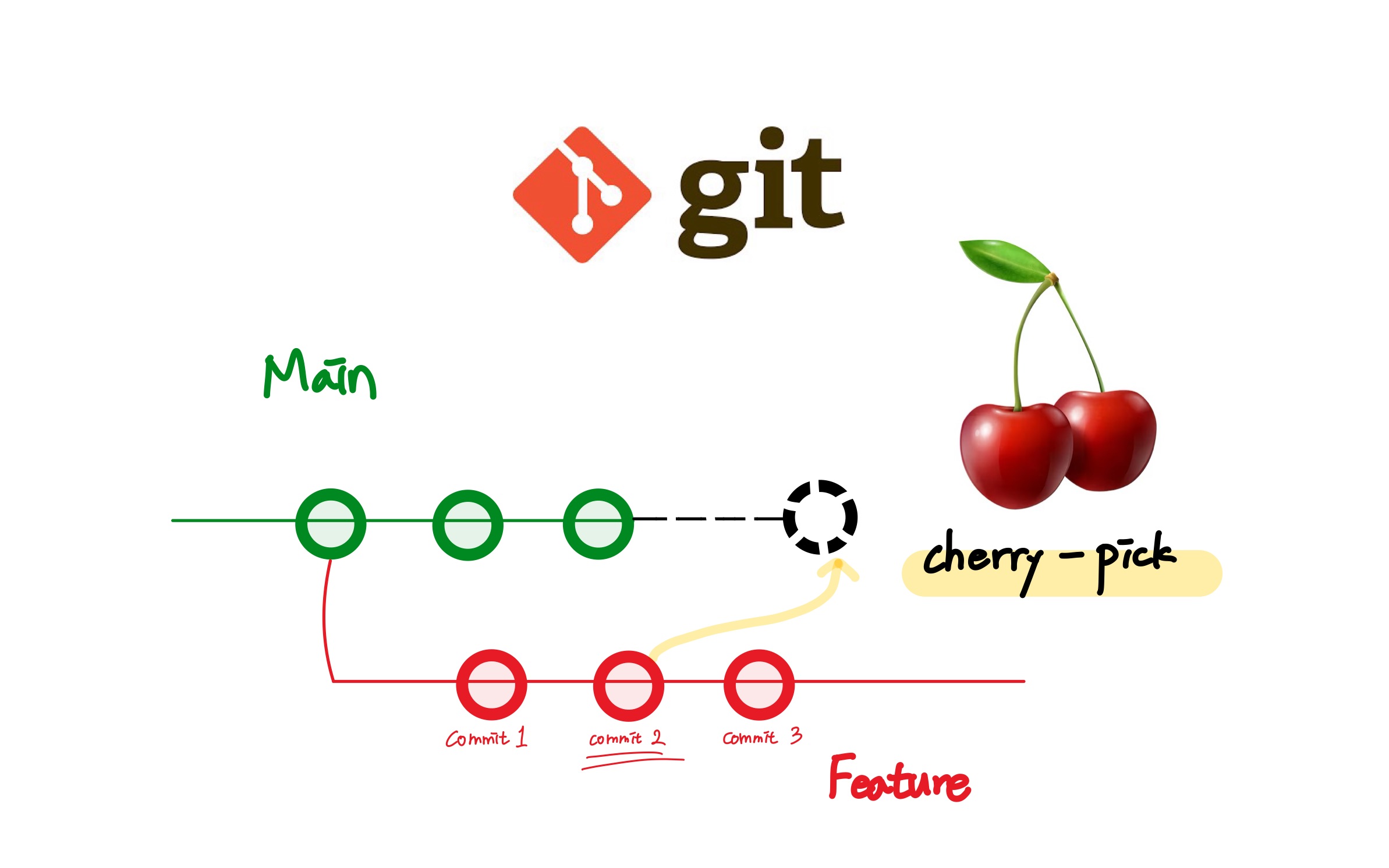
In der Welt der Softwareentwicklung herrscht ein gefährlicher Glaube vor: Die Vorstellung, dass wir die Geschichte unseres Codes wie ein Skalpell führen können. Entwickler greifen oft in Momenten der Not zu Git Cherry Pick Multiple Commits, in der Hoffnung, punktuelle Verbesserungen aus einem chaotischen Feature-Branch in den stabilen Hauptzweig zu retten. Man stellt sich das wie das Pflücken der reifsten Kirschen aus einem fremden Garten vor. Doch die Realität in den Rechenzentren und Entwicklungsabteilungen von Berlin bis San Francisco sieht anders aus. Wer glaubt, durch das isolierte Herausgreifen von Änderungen die Integrität seines Systems zu wahren, ignoriert die fundamentale Natur gerichteter azyklischer Graphen, auf denen Git basiert. Diese Technik ist kein Präzisionswerkzeug, sondern oft eine Bankrotterklärung gegenüber einer sauberen Branch-Strategie. Es ist die technische Entsprechung dazu, eine Seite aus einem Buch zu reißen und sie in ein anderes zu kleben, während man hofft, dass die Seitenzahlen und der Kontext der Handlung wie durch ein Wunder harmonieren.
Die gefährliche Verlockung von Git Cherry Pick Multiple Commits
Das Problem beginnt bei der Wahrnehmung. Ein Commit ist in Git kein isoliertes Paket von Änderungen, auch wenn die grafischen Benutzeroberflächen uns das vorgaukeln. Er ist ein Schnappschuss eines Zustands, der untrennbar mit seinen Vorfahren verbunden ist. Wenn du dich entscheidest, Git Cherry Pick Multiple Commits anzuwenden, erzeugst du technisch gesehen Duplikate. Diese neuen Commits besitzen zwar denselben Inhalt wie die Originale, haben aber eine völlig andere Identität im System. Linus Torvalds, der Schöpfer von Git, entwarf das System für den Linux-Kernel, um die Abstammung von Code lückenlos nachzuverfolgen. Durch das manuelle Verschieben von Commit-Ketten zerstörst du genau diese Abstammungslinie. Ich habe miterlebt, wie große Architekturprojekte bei deutschen Automobilzulieferern ins Stocken gerieten, weil die Historie durch solche Eingriffe so zerklüftet war, dass kein automatisches Merge-Tool mehr wusste, welcher Stand nun der rechtmäßige Erbe des Master-Branches war. Die vermeintliche Zeitersparnis am Nachmittag führt unweigerlich zu einer Nachtschicht drei Wochen später, wenn die Konflikte beim finalen Zusammenführen unauflösbar werden.
Wenn das Skalpell zur Axt wird
Skeptiker dieser kritischen Sichtweise führen gern an, dass Hotfixes oder dringende Sicherheits-Patches keine andere Wahl lassen. Sie argumentieren, man könne nicht den gesamten instabilen Entwicklungszweig übernehmen, nur um eine einzige Lücke zu schließen. Das klingt vernünftig. Es ist das stärkste Argument der Befürworter. Doch hier liegt der Denkfehler: Wenn dein Workflow dich dazu zwingt, regelmäßig Code-Fragmente hin und her zu schieben, ist nicht das Fehlen eines Befehls das Problem, sondern die Struktur deiner Arbeit. Eine saubere Trennung von Belangen, das Prinzip der „Separation of Concerns“, sollte sich in der Struktur der Branches widerspiegeln. Werden Funktionen so eng miteinander verzahnt, dass man sie einzeln herauspicken muss, hat man bereits gegen die Grundregeln des modularen Designs verstoßen. Das Werkzeug wird dann zum Alibi für schlechte Planung. Es ist eine Krücke, die man als Rennrad verkauft. In der Praxis führt dieses Vorgehen zu sogenannten „Ghost Commits“, die im System herumspuken und bei späteren Merges für Verwirrung sorgen, weil Git denkt, es handele sich um völlig neue Änderungen, obwohl der Inhalt bereits vorhanden ist.
Warum die Historie mehr ist als nur Text
Ein Git-Verlauf ist eine Erzählung. Er dokumentiert das „Warum“ hinter einer Entscheidung. Wenn wir dieses Feld der Softwarearchäologie betrachten, stellen wir fest, dass die semantische Bedeutung eines Codes oft in den Commits steckt, die ihn umgeben. Ein Refactoring hier, eine Fehlerbehebung dort – alles ist Teil eines größeren Ganzen. Das Verfahren, das wir als Git Cherry Pick Multiple Commits bezeichnen, reißt diese Zusammenhänge auseinander. Es ist, als würde man ein Zitat aus einem Interview nehmen und es in einen völlig anderen Artikel einbauen. Der Wortlaut mag stimmen, aber die Intention geht verloren. In hochgradig regulierten Branchen, etwa in der Medizintechnik oder im Finanzsektor, kann das fatale Folgen haben. Auditoren verlangen eine lückenlose Rückverfolgbarkeit. Wenn ein Prüfer sieht, dass Code-Teile ohne erkennbare Verbindung zum ursprünglichen Review-Prozess im Hauptzweig auftauchen, entstehen berechtigte Zweifel an der Prozesssicherheit. Die technische Schuld, die man hier aufnimmt, wird nicht in Zinsen gezahlt, sondern in der Erosion des Vertrauens in die eigene Codebasis.
Die Illusion der Kontrolle über den Datenstrom
Man kann das Ganze mit einem Fluss vergleichen. Ein Branch ist ein Seitenarm. Normalerweise möchte man, dass dieser Seitenarm irgendwann wieder in den Hauptstrom mündet. Werden nun einzelne Eimer Wasser aus dem Seitenarm entnommen und vorne in den Hauptfluss gekippt, ändert das die Dynamik. Der Seitenarm existiert weiter, aber er ist jetzt inkonsistent zum Hauptstrom. Je öfter man das tut, desto weniger haben die beiden Gewässer miteinander zu tun, obwohl sie eigentlich denselben Ursprung haben. Professionelles Configuration Management, wie es in großen Open-Source-Projekten praktiziert wird, setzt stattdessen auf Rebase-Strategien oder kurzlebige Feature-Branches. Diese Methoden zwingen den Entwickler dazu, sich mit der Realität des Codes auseinanderzusetzen, anstatt eine künstliche Parallelwelt zu erschaffen. Es geht darum, Schmerzen frühzeitig zu spüren, anstatt sie durch kosmetische Eingriffe in die Zukunft zu verschieben. Wer behauptet, solche manuellen Eingriffe seien ein Zeichen von Expertise, verwechselt handwerkliches Geschick mit riskanter Improvisation. Wahre Meisterschaft zeigt sich darin, das System so zu nutzen, dass solche Operationen schlichtweg nie notwendig werden.
Wer die Integrität seiner Software liebt, sollte die Geschichte seines Codes als unantastbares Protokoll begreifen und nicht als einen Baukasten, aus dem man sich nach Belieben bedient.



