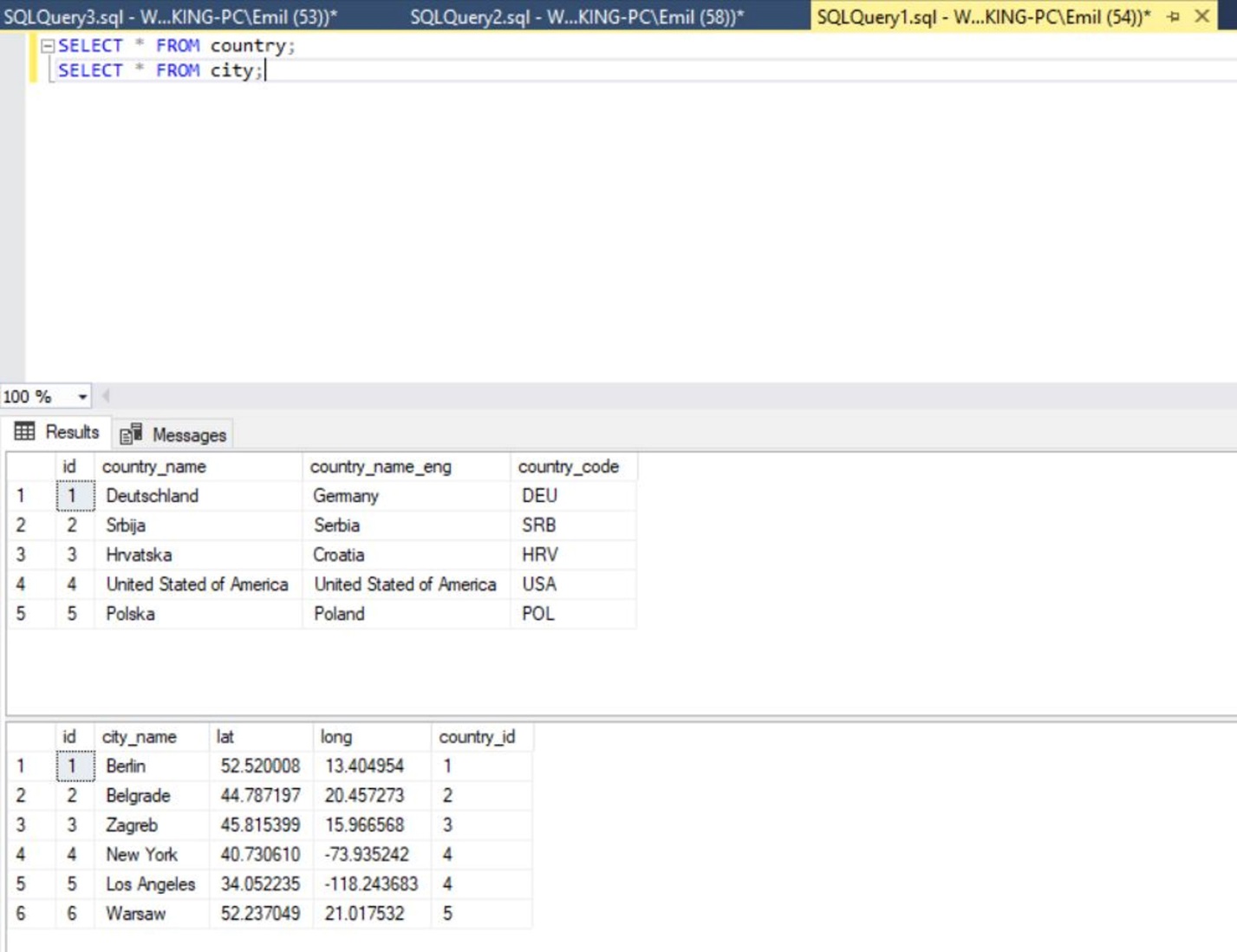
In den klimatisierten Serverräumen der Finanzmetropole Frankfurt am Main entscheidet oft ein einziger Befehl über die Stabilität ganzer Systeme, doch kaum jemand spricht über die architektonische Arroganz, mit der wir Daten von A nach B schieben. Die meisten Entwickler betrachten die Übertragung von Datensätzen als eine triviale Pflichtaufgabe, eine Art digitalen Umzugskarton, den man einfach von einer Tabelle in die nächste wirft. Wer jedoch glaubt, dass die bloße Effizienz der Mechanik hinter Insert Into With Select Sql das Ende der Fahnenstange darstellt, der irrt gewaltig. Es ist eben nicht nur ein Werkzeug zur Datenmigration. Vielmehr handelt es sich um eine operative Operation am offenen Herzen einer Datenbank, die bei falscher Handhabung die gesamte Integrität einer relationalen Struktur zerfressen kann. Wir haben uns angewöhnt, Komplexität durch Abstraktion zu maskieren, während die wahre Macht und die wahren Risiken tief in der SQL-Syntax verborgen liegen.
Ich habe Systeme gesehen, die unter der Last schlecht geplanter Datenkopien zusammenbrachen, nur weil jemand dachte, dass Geschwindigkeit wichtiger sei als Konsistenz. Der Mythos besagt, dass die direkte Verbindung von Abfrage und Einfügung der Goldstandard für Performance ist. Das stimmt zwar technisch gesehen oft, aber es ignoriert die Realität der Sperrmechanismen und der Transaktionsprotokolle. Wer Datenmengen im Millionenbereich ohne Rücksicht auf die zugrunde liegenden Indizes bewegt, provoziert Deadlocks, die den Geschäftsbetrieb eines mittelständischen Unternehmens innerhalb von Sekunden zum Stillstand bringen. Es ist Zeit, diese mechanistische Sichtweise abzulegen und die strukturellen Implikationen dieser Operation als das zu sehen, was sie sind: ein riskantes Manöver, das absolute Präzision verlangt. Derweil können Sie andere Nachrichten hier erkunden: cessna c208 grand caravan squawk transponder.
Die Illusion der atomaren Sicherheit beim Insert Into With Select Sql
Wenn wir über Datenbanktransaktionen sprechen, schwingt immer ein Gefühl der Sicherheit mit. Das Versprechen der Atomarität suggeriert uns, dass entweder alles oder gar nichts passiert. Das ist eine beruhigende Vorstellung für jeden, der nachts ruhig schlafen will. Doch die Realität bei der Verwendung von Insert Into With Select Sql sieht oft anders aus, besonders wenn man die Isolationsebenen der Datenbank vernachlässigt. In einer hochgradig parallelisierten Umgebung ist der Vorgang eben nicht isoliert von der Außenwelt. Während der Select-Teil Daten liest, können andere Prozesse diese bereits verändern. Was in der Ziel-Tabelle landet, ist dann kein exaktes Abbild der Wahrheit, sondern ein Zerrbild eines flüchtigen Moments, das durch sogenannte Phantom-Reads oder Dirty-Reads verfälscht wurde.
Man muss sich klarmachen, dass die Performance-Vorteile dieser Methode direkt mit dem Verzicht auf Sicherheitsnetze erkauft werden. Viele Datenbanksysteme neigen dazu, bei solchen Massenoperationen die Sperren zu eskalieren. Das bedeutet, dass statt einzelner Zeilen plötzlich ganze Tabellenseiten oder gar die komplette Tabelle für andere Schreibzugriffe gesperrt werden. Ich habe Situationen erlebt, in denen ein eigentlich simpler Datenübertrag die Buchhaltung eines Logistikunternehmens für Stunden lahmgelegt hat. Die Techniker standen vor den Monitoren und verstanden nicht, warum die Datenbank nicht mehr reagierte. Der Grund war simpel: Die Operation hatte sich so tief in die Ressourcen gefressen, dass keine anderen Prozesse mehr durchkamen. Es ist ein klassischer Fall von technischer Kurzsichtigkeit, bei dem der Fokus auf den Durchsatz die Verfügbarkeit opfert. Wer mehr erfahren möchte über die Geschichte, findet bei CHIP eine informative Übersicht.
Skeptiker werden nun einwenden, dass moderne Datenbanksysteme wie PostgreSQL oder Microsoft SQL Server über hochentwickelte Optimierer verfügen, die genau solche Szenarien verhindern sollen. Das ist theoretisch korrekt. In der Praxis jedoch stoßen diese Optimierer an ihre Grenzen, sobald die Datenmodelle komplexer werden und die Indizierung nicht perfekt auf die Abfrage abgestimmt ist. Ein Optimierer ist kein Hellseher. Er arbeitet mit Statistiken, die oft veraltet sind. Wenn du dich blind auf die Automatik verlässt, spielst du russisches Roulette mit deiner Systemperformance. Der Fachmann weiß, dass die manuelle Kontrolle der Transaktionsgröße und das bewusste Setzen von Sperren unumgänglich sind, wenn man nicht riskieren will, dass der Server unter der eigenen Last kapituliert.
Strategische Präzision statt roher Gewalt
Ein weit verbreiteter Irrtum in der Softwareentwicklung ist die Annahme, dass mehr Hardware jedes Softwareproblem lösen kann. Wir werfen mehr Arbeitsspeicher und schnellere NVMe-Speicher auf die Datenbank, nur um festzustellen, dass die Latenzen bei großen Operationen trotzdem steigen. Die Wahrheit ist, dass die Architektur der Datenbewegung selbst das Problem ist. Anstatt eine riesige Menge an Informationen in einem einzigen Rutsch zu verschieben, sollte man über Batch-Verarbeitung nachdenken. Das klingt im ersten Moment kontraintuitiv, da es die Gesamtlaufzeit verlängern könnte. Aber es schont die Ressourcen und hält das System reaktionsfähig. Es geht um die Balance zwischen roher Gewalt und chirurgischer Präzision.
In meiner Zeit als Berater für Datenbankarchitekturen habe ich oft gesehen, wie Unternehmen versuchten, ihre Altdatenbestände zu bereinigen. Sie nutzten die hier besprochene Methode, um Milliarden von Zeilen in neue Schemata zu pressen. Das Ergebnis war fast immer ein Desaster. Nicht wegen der Syntax, sondern wegen der fehlenden Berücksichtigung des Log-Speichers. Jede eingefügte Zeile muss protokolliert werden. Wenn das Transaktionslog voll läuft, bricht die gesamte Operation ab und die Datenbank muss mühsam alles zurückrollen. Das kann Stunden dauern. Wer hier nicht mit Bedacht vorgeht, riskiert eine Ausfallzeit, die weit über das geplante Wartungsfenster hinausgeht. Man sollte sich also fragen: Ist die schnellste Methode auch die sicherste? Meistens lautet die Antwort nein.
Die Kunst besteht darin, die Datenmenge in verdaubare Häppchen zu unterteilen. Das ist kein Zeichen von Schwäche oder mangelndem Vertrauen in die Technik. Es ist ein Zeichen von Professionalität. Ein guter Ingenieur weiß, dass ein System nur so stark ist wie sein schwächstes Glied, und bei einer Massendatenoperation ist dieses Glied oft das E/A-Subsystem oder der Sperr-Manager. Indem man die Last verteilt, minimiert man das Risiko eines totalen Systemversagens. Man gewinnt dadurch zwar keinen Preis für die kürzeste Code-Zeile, aber man gewinnt das Vertrauen der Nutzer, deren Anwendungen flüssig weiterlaufen, während im Hintergrund gewaltige Datenberge versetzt werden.
Warum die Logik der Mengenlehre oft in die Irre führt
SQL basiert auf der Mengenlehre. Das ist mathematisch elegant und logisch bestechend. Aber Computer sind keine mathematischen Abstraktionen. Sie sind physische Maschinen mit begrenzten Ressourcen. Wenn du eine Menge definierst, die du von einem Ort zum anderen bewegen willst, denkst du in Ergebnismengen. Die Datenbank muss jedoch in Ausführungsplänen denken. Ein häufiger Fehler ist die Annahme, dass eine Filterung innerhalb der Abfrage die Last proportional verringert. Doch oft führt eine komplexe Where-Klausel dazu, dass die Datenbank erst recht ins Schwitzen kommt, weil sie temporäre Tabellen im Arbeitsspeicher anlegen muss, bevor der eigentliche Schreibvorgang beginnt.
Man darf auch den Einfluss von Triggern und Constraints nicht unterschätzen. Jedes Mal, wenn ein Datensatz in die Zieltabelle geschrieben wird, müssen eventuell vorhandene Prüfroutinen laufen. Bei einer Einzelzeile merkt man das nicht. Bei einer Million Zeilen wird aus einer Millisekunde plötzlich eine Ewigkeit. Es ist daher oft klüger, Constraints während der Operation temporär zu deaktivieren und die Validierung im Anschluss als separaten Schritt durchzuführen. Das erfordert natürlich ein höheres Maß an Disziplin und eine genaue Kenntnis der Datenqualität. Aber wer diese Disziplin nicht aufbringt, sollte ohnehin nicht an den Fundamenten einer Unternehmensdatenbank arbeiten. Es gibt keine Abkürzung zur Exzellenz, und wer versucht, eine zu nehmen, zahlt am Ende meistens drauf.
Die Befürworter einer rein deklarativen Programmierung werden nun argumentieren, dass man der Datenbank lediglich sagen sollte, was man will, und nicht, wie sie es tun soll. Das ist ein schönes Ideal, das in der akademischen Welt wunderbar funktioniert. In der harten Realität der Enterprise-IT, wo Terabytes an Daten über den Bus geschoben werden, ist dieses Vertrauen jedoch oft fehl am Platz. Man muss die Interna verstehen. Man muss wissen, wie der Speicher am Besten genutzt wird und wie man Konflikte vermeidet. Die rein theoretische Betrachtung von Insert Into With Select Sql führt dazu, dass man die physischen Grenzen der Hardware ignoriert, was unweigerlich zu Problemen führt. Es ist wie beim Autofahren: Man kann zwar immer im höchsten Gang fahren, um Sprit zu sparen, aber am Berg wird der Motor irgendwann abwürgen.
Die kulturelle Komponente der Datenpflege
Es ist interessant zu beobachten, dass die Art und Weise, wie wir mit Datenoperationen umgehen, viel über die Kultur einer IT-Abteilung aussagt. In Umgebungen, in denen "Quick and Dirty" das Motto ist, werden solche Befehle oft ohne Vorabprüfung auf die Produktionsumgebung losgelassen. Man vertraut darauf, dass es schon gut gehen wird. In hochgradig regulierten Branchen wie dem Versicherungswesen oder der Medizintechnik herrscht dagegen eine fast schon paranoide Vorsicht. Dort werden solche Skripte erst in tagelangen Testreihen auf Staging-Systemen validiert, die eine exakte Kopie der Produktion sind. Diese Vorsicht ist nicht Ausdruck von Inkompetenz, sondern von tiefer Erfahrung.
Wir müssen begreifen, dass Daten das wichtigste Kapital der Moderne sind. Sie wie Abfall zu behandeln, den man einfach nur umschichtet, ist fahrlässig. Jede Transformation, jedes Kopieren und jedes Einfügen ist eine Chance, den Wert der Daten zu erhöhen oder ihn durch Inkonsistenzen zu vernichten. Die technische Umsetzung ist dabei nur die Spitze des Eisbergs. Darunter liegt eine Schicht aus Verantwortung und strategischer Planung. Wenn ein Unternehmen beschließt, seine Datenbankstruktur zu modernisieren, dann ist die technische Wahl des Befehls nur ein Detail. Die eigentliche Arbeit liegt in der Analyse der Datenbeziehungen und der Auswirkungen auf die abhängigen Applikationen.
Oft wird vergessen, dass nachgelagerte Systeme wie Data Warehouses oder Analyse-Tools auf die zeitnahe Verfügbarkeit der Daten angewiesen sind. Wenn eine massive Schreiboperation die Quellsysteme blockiert, bricht die gesamte Informationskette zusammen. Das Management erhält keine Berichte mehr, die Logistik kann keine Routen planen und der Kundenservice sieht keine aktuellen Bestellungen. Ein kleiner Fehler in der SQL-Syntax oder eine falsch eingeschätzte Datenmenge hat somit Auswirkungen, die weit über die IT-Abteilung hinausgehen. Es ist ein Dominoeffekt, den man nur durch weitsichtiges Handeln verhindern kann.
Ein neues Verständnis für digitale Architektur
Wenn wir uns die Entwicklung der letzten Jahrzehnte ansehen, wird deutlich, dass wir uns von einfachen statischen Datenbeständen hin zu dynamischen, hochvernetzten Ökosystemen bewegt haben. In diesem Umfeld ist die Effizienz einer Operation nicht mehr nur an ihrer Ausführungszeit messbar. Sie misst sich an ihrer Resilienz und ihrer Fähigkeit, sich in das Gesamtgefüge einzupassen, ohne Störungen zu verursachen. Wir müssen lernen, die Werkzeuge, die uns zur Verfügung stehen, mit mehr Respekt zu behandeln. Ein Skalpell in der Hand eines Chirurgen rettet Leben, in der Hand eines Laien kann es tödlich sein. Ähnlich verhält es sich mit mächtigen Datenbankbefehlen.
Ich plädiere für eine Rückkehr zum Handwerklichen. Weg von der blinden Nutzung von Frameworks, die uns vorgaukeln, dass wir uns um die Details nicht mehr kümmern müssen. Wir müssen die Details wieder lieben lernen. Wir müssen verstehen, warum ein Index bei einer bestimmten Abfrage funktioniert und warum er bei einer anderen kläglich versagt. Wir müssen die Transaktionslogs beobachten und ein Gefühl dafür entwickeln, wann ein System an seine Grenzen stößt. Nur wer die Tiefe der Materie begreift, kann die Oberfläche sicher navigieren. Das bedeutet auch, dass wir unsere Ausbildung und unser Training in der IT wieder stärker auf die Grundlagen fokussieren müssen, anstatt nur den neuesten Trends hinterherzulaufen.
Die wahre Meisterschaft zeigt sich nicht darin, wie komplex man ein Problem lösen kann, sondern wie einfach und sicher man es löst. Manchmal ist der Verzicht auf die vermeintlich schnellste Methode der klügere Weg. Es erfordert Mut, dem Management zu sagen, dass ein Prozess länger dauert, weil man ihn sicher gestalten will. Aber dieser Mut zahlt sich langfristig aus, wenn die Systeme stabil laufen und keine nächtlichen Notfalleinsätze nötig sind. Es ist eine Frage der professionellen Ehre, Systeme zu bauen, die nicht nur funktionieren, sondern die auch unter Last ihre Würde bewahren.
Wer die wahre Natur von Datenverschiebungen versteht, sieht in ihnen keine lästige Pflicht, sondern die Architektur der modernen Welt, in der Stabilität schwerer wiegt als die flüchtige Illusion von Geschwindigkeit.



