Stell dir vor, du sitzt in einer Bibliothek mit tausend Büchern, die alle dasselbe Thema behandeln, sich aber ständig widersprechen. Das ist der Alltag in der modernen Forschung. Forscher veröffentlichen jedes Jahr Millionen von Studien, und oft kommt eine Untersuchung zu einem völlig anderen Ergebnis als die nächste. Wer soll da noch durchblicken? Hier kommt die Meta Analysis Of Meta Analyses ins Spiel, die oft auch als Umbrella Review oder Overview of Reviews bezeichnet wird. Sie ist das Werkzeug für alle, die keine Lust mehr auf widersprüchliche Einzelbefunde haben. Anstatt hunderte kleine Experimente mühsam selbst auszuwerten, nimmt diese Methode bereits bestehende statistische Zusammenfassungen unter die Lupe. Es ist die höchste Ebene der Evidenz. Wenn du wissen willst, was wirklich Stand der Dinge ist, führt kein Weg an dieser Form der Wissensverdichtung vorbei.
Warum wir eine Meta Analysis Of Meta Analyses heute dringender brauchen als jemals zuvor
In der medizinischen Forschung und den Sozialwissenschaften gibt es ein riesiges Problem. Es nennt sich Publikationsbias. Forscher neigen dazu, nur signifikante Ergebnisse zu veröffentlichen. Die Studien, die nichts Bahnbrechendes herausgefunden haben, verschwinden in der Schublade. Das verzerrt unser Bild der Realität gewaltig. Wenn du zehn Meta-Analysen zu einem Thema wie der Wirksamkeit von Antidepressiva liest, wirst du feststellen, dass selbst diese Zusammenfassungen unterschiedliche Schwerpunkte setzen. Manche inkludieren nur klinische Studien, andere nehmen Beobachtungsstudien hinzu. Das Ergebnis ist Verwirrung.
Die übergeordnete Analyse räumt hier auf. Sie vergleicht die Methoden der bestehenden Reviews. Sie schaut genau hin, welche Primärstudien doppelt gezählt wurden. Das ist ein häufiger Fehler: Eine große Studie wird in fünf verschiedenen Analysen zitiert und bekommt dadurch ein viel zu hohes Gewicht. Die Dach-Analyse korrigiert solche Verzerrungen. Wer nur auf eine einzelne statistische Auswertung vertraut, sieht oft den Wald vor lauter Bäumen nicht.
Die Hierarchie der wissenschaftlichen Beweiskraft
In der Wissenschaft gibt es eine klare Rangordnung. Ganz unten stehen Expertenmeinungen. Das ist im Grunde nur Bauchgefühl mit Titel. Darüber kommen Fallberichte und Beobachtungsstudien. Diese sind zwar nützlich, beweisen aber keine Kausalität. Danach folgen die randomisierten kontrollierten Studien (RCTs). Diese gelten lange als Goldstandard. Aber selbst ein RCT kann durch Zufall oder eine kleine Stichprobe falsch liegen.
Deshalb erfand man die klassische Meta-Analyse. Sie fasst viele RCTs zusammen. Aber was passiert, wenn es zu einem Thema mittlerweile zwanzig solcher Zusammenfassungen gibt? Dann rutscht die Wissenschaft eine Stufe höher. Diese neue Form der Auswertung steht an der Spitze der Pyramide. Sie ist die ultimative Instanz. Wenn diese Methode gut durchgeführt wird, bietet sie eine Sicherheit, die kein einzelner Forscher allein erreichen kann.
Das Problem mit der Datenflut in der Medizin
Gerade in der Medizin ist die Lage kritisch. Schau dir die Cochrane Library an. Dort findest du tausende hochwertige Reviews. Aber für einen Arzt im stressigen Klinikalltag ist es unmöglich, all das zu lesen. Er braucht eine Antwort auf die Frage: Welche Behandlung funktioniert bei 90 % der Patienten? Eine Dach-Auswertung liefert genau diese komprimierte Antwort. Sie filtert den Lärm heraus. Sie zeigt auf, wo die Evidenz noch lückenhaft ist. Das spart Zeit und rettet am Ende Leben.
Schritt für Schritt zur eigenen Meta Analysis Of Meta Analyses
Wer glaubt, man könne so eine Analyse an einem Nachmittag schreiben, irrt sich gewaltig. Es ist eine Sysiphos-Arbeit. Zuerst musst du eine präzise Fragestellung formulieren. Diese muss breit genug sein, um mehrere Reviews abzudecken, aber spezifisch genug, um verwertbare Daten zu liefern. Danach beginnt die systematische Suche. Du durchkämmst Datenbanken wie PubMed, PsycINFO oder Scopus. Du suchst nicht nach Rohdaten, sondern nach den statistischen Zusammenfassungen anderer Autoren.
Der kritische Punkt ist die Qualitätsbewertung. Nicht jede veröffentlichte Arbeit ist gut. Du musst Instrumente wie AMSTAR 2 verwenden. Damit prüfst du, ob die Autoren der Vorarbeiten sauber gearbeitet haben. Haben sie nach unveröffentlichten Daten gesucht? War ihre Suchstrategie transparent? Wenn eine Analyse methodisch schwach ist, flieht sie aus deinem Datensatz. Nur die besten Überprüfungen dürfen bleiben.
Überlappungen erkennen und eliminieren
Das größte technische Hindernis ist die Überlappung der Primärstudien. Stell dir vor, Studie A von Müller et al. aus dem Jahr 2018 ist so gut, dass sie in jeder der zehn von dir gefundenen Analysen auftaucht. Wenn du die Ergebnisse dieser zehn Arbeiten einfach mittelst, zählst du Müller et al. zehnmal. Das Ergebnis wäre völlig wertlos.
Du musst eine Matrix erstellen. In den Zeilen stehen die Primärstudien, in den Spalten die Meta-Analysen. Dann markierst du, welche Studie wo auftaucht. Es gibt mathematische Formeln wie den "Corrected Covered Area" (CCA) Score, um diesen Grad der Überschneidung zu berechnen. Wenn die Überschneidung zu hoch ist, musst du deine Strategie anpassen. Das ist echte Detektivarbeit. Man wühlt sich durch Literaturverzeichnisse, bis die Augen brennen. Aber nur so verhinderst du statistische Geisterbilder.
Die Wahl der richtigen statistischen Modelle
Man kann nicht einfach Äpfel mit Birnen vergleichen. Manche Autoren nutzen das Fixed-Effects-Modell. Andere bevorzugen das Random-Effects-Modell. Ersteres geht davon aus, dass es einen einzigen wahren Effekt gibt. Letzteres akzeptiert, dass Ergebnisse zwischen verschiedenen Populationen schwanken können. In einer Dach-Analyse musst du entscheiden, wie du mit dieser Heterogenität umgehst.
Meistens ist ein Random-Effects-Ansatz sinnvoller. Die Welt ist komplex. Menschen in Deutschland reagieren anders auf eine Therapie als Menschen in Brasilien. Die Statistik muss diesen Unterschieden Raum geben. Du berichtest dann nicht nur einen einzelnen Wert, sondern auch das Konfidenzintervall. Das zeigt, wie sicher wir uns bei der Sache eigentlich sind. Ein schmales Intervall bedeutet hohe Sicherheit. Ein breites Intervall heißt: Wir wissen es eigentlich immer noch nicht genau.
Die häufigsten Fehler bei der Erstellung dieser Analysen
Ich habe viele Arbeiten gesehen, die kläglich gescheitert sind. Der häufigste Fehler ist Faulheit bei der Suche. Wer nur bei Google Scholar sucht, verpasst die Hälfte. Eine gute Recherche erfordert den Einsatz von Booleschen Operatoren und eine manuelle Sichtung von tausenden Titeln. Ein weiterer Fehler ist das Ignorieren der "Grey Literature". Das sind Berichte, Dissertationen oder Konferenzbeiträge, die nie in Fachzeitschriften erschienen sind. Oft enthalten genau diese Texte die negativen Ergebnisse, die so wichtig für ein ehrliches Gesamtbild sind.
Ein zweiter massiver Fehler ist die mangelnde Transparenz. Ein Leser muss in der Lage sein, deine Schritte exakt nachzuvollziehen. Wenn du nicht genau dokumentierst, warum du eine bestimmte Arbeit ausgeschlossen hast, verliert deine gesamte Untersuchung an Glaubwürdigkeit. In der Wissenschaft ist Vertrauen gut, aber Reproduzierbarkeit ist alles. Wer hier schlampt, produziert nur weiteren Datenmüll.
Qualitätsprüfung mit AMSTAR 2
Wenn du wissen willst, ob eine Zusammenfassung etwas taugt, schau dir das AMSTAR-Protokoll an. Es stellt Fragen wie: Wurde die Forschung vorab registriert? Gab es mindestens zwei unabhängige Gutachter für die Auswahl der Studien? Wurde das Risiko für Bias in den eingeschlossenen Arbeiten bewertet? Wenn ein Review diese Fragen mit "Nein" beantwortet, solltest du vorsichtig sein. Eine hochwertige Dach-Untersuchung ist nur so stark wie ihr schwächstes Glied.
Es geht darum, die Spreu vom Weizen zu trennen. Oft bleiben von ursprünglich 50 identifizierten Arbeiten am Ende nur fünf oder sechs übrig, die wirklich belastbar sind. Das ist frustrierend, aber notwendig. Lieber eine präzise Aussage basierend auf wenigen exzellenten Quellen als eine vage Vermutung basierend auf einem Berg von Mittelmäßigkeit.
Umgang mit widersprüchlichen Ergebnissen
Was machst du, wenn zwei hochqualitative Reviews zu völlig unterschiedlichen Schlüssen kommen? Das ist der Moment, in dem die Meta Analysis Of Meta Analyses zeigt, was sie kann. Du suchst nach den Gründen für die Diskrepanz. Haben die Autoren unterschiedliche Endpunkte definiert? War der Beobachtungszeitraum verschieden? Oft liegt die Wahrheit in den Details der Definitionen. Die Dach-Analyse fungiert hier als Schiedsrichter. Sie erklärt dem Leser, warum die Unterschiede existieren. Das bietet einen viel tieferen Einblick als jede Einzelstudie.
Praktische Anwendung in der realen Welt
In der Politikberatung sind solche umfassenden Auswertungen Gold wert. Wenn eine Regierung entscheiden muss, ob sie Milliarden in ein neues Bildungsprogramm investiert, verlässt sie sich nicht auf eine einzelne Studie aus einem kleinen Dorf. Sie braucht die Sicherheit der aggregierten Evidenz. Hier werden Entscheidungen getroffen, die Millionen Menschen betreffen. Da darf man sich keine methodischen Fehler erlauben.
Auch im Marketing oder in der Psychologie sehen wir diesen Trend. Überall dort, wo Daten im Überfluss vorhanden sind, wächst der Bedarf an Ordnung. Wir leben nicht mehr in einer Zeit des Informationsmangels. Wir leiden an einer Informationsoverload. Die Kunst besteht heute darin, das Wichtige vom Unwichtigen zu trennen. Die Fähigkeit, komplexe Datenmengen zu synthetisieren, ist eine der wichtigsten Kompetenzen des 21. Jahrhunderts.
Beispiele aus der klinischen Psychologie
Nehmen wir das Thema Achtsamkeitsmeditation. Es gibt tausende Studien dazu. Manche sagen, es hilft gegen alles von Rückenschmerzen bis Depression. Andere sagen, es ist kaum besser als ein Placebo. Wenn man hier eine Dach-Analyse durchführt, erkennt man schnell ein Muster: Bei leichten Depressionen ist der Effekt stabil, bei schweren klinischen Fällen reicht Meditation allein oft nicht aus. Solche differenzierten Aussagen sind nur möglich, wenn man die gesamte verfügbare Literatur von oben betrachtet.
Ein weiteres Beispiel ist die Debatte um Videospiele und Aggression. Jahrelang gab es Studien, die in beide Richtungen zeigten. Erst die ganz großen Zusammenfassungen konnten zeigen, dass der Effekt – wenn er überhaupt existiert – verschwindend gering ist im Vergleich zu anderen sozialen Faktoren. Das hat die öffentliche Debatte massiv beruhigt. Ohne die Kraft der aggregierten Daten würden wir heute noch über Verbote diskutieren, die an der Realität vorbeigehen.
Relevanz für technologische Entwicklungen
In der KI-Forschung sehen wir eine ähnliche Entwicklung. Ständig erscheinen neue Benchmarks für Sprachmodelle. Ein Modell ist heute das beste, morgen ein anderes. Eine systematische Einordnung dieser Benchmarks hilft Entwicklern zu verstehen, welche Architektur wirklich einen Durchbruch darstellt. Es geht weg vom Hype, hin zu belegbaren Fakten. Wer die Mechanismen der Wissensaggregation versteht, kann Trends von Substanz unterscheiden.
Die Zukunft der Wissenssynthese
Wir stehen erst am Anfang. Mit der Hilfe von Machine Learning wird es bald möglich sein, solche umfassenden Auswertungen fast in Echtzeit zu erstellen. Stell dir eine Software vor, die jede Sekunde neue Publikationen liest, deren Qualität prüft und das globale Wissen sofort aktualisiert. Das wäre das Ende der veralteten Lehrbücher. Wissen wäre ein flüssiger, sich ständig selbst korrigierender Prozess.
Aber bis dahin sind wir auf menschliche Experten angewiesen. Wir brauchen Leute, die die Statistik verstehen und die Ergebnisse einordnen können. Eine Maschine kann Zahlen korrelieren, aber sie versteht oft den Kontext nicht. Warum wurde eine Studie in einem bestimmten Land durchgeführt? Welche kulturellen Faktoren spielten eine Rolle? Das menschliche Urteilsvermögen bleibt der Kern der Wissenschaft.
Ethische Verantwortung der Forscher
Wer eine solche Arbeit verfasst, trägt eine große Verantwortung. Da diese Analysen oft als "letztes Wort" zu einem Thema wahrgenommen werden, können Fehler fatale Folgen haben. Ein falsch positiver Befund kann dazu führen, dass wirkungslose Medikamente verschrieben werden. Ein falsch negativer Befund kann verhindern, dass hilfreiche Therapien finanziert werden. Es ist ein Spiel mit hohen Einsätzen.
Deshalb ist absolute Integrität gefragt. Man darf keine Ergebnisse schönen, um die eigene Hypothese zu stützen. In der Wissenschaft sollte es nie darum gehen, Recht zu haben. Es geht darum, herauszufinden, was wahr ist. Auch wenn die Wahrheit unbequem ist oder die eigene bisherige Arbeit in Frage stellt. Wahre Größe zeigt sich darin, die eigenen Fehler öffentlich zu korrigieren.
Der Einfluss auf die Forschungsförderung
Geldgeber wie die Deutsche Forschungsgemeinschaft (DFG) schauen immer genauer hin. Sie wollen nicht die hundertste Studie zum gleichen Thema finanzieren, die keine neuen Erkenntnisse bringt. Sie fordern eine klare Einordnung in den bestehenden Wissensstand. Eine fundierte Übersichtsarbeit zeigt auf, wo die "weißen Flecken" auf der Landkarte sind. Sie leitet die Forschungsgelder dorthin, wo sie den größten Nutzen bringen. Das macht das System effizienter.
Praktische Schritte für deine Recherche
Wenn du jetzt selbst eine solche Untersuchung planen willst, fang klein an. Wähle ein Thema, das dich wirklich brennt interessiert. Ohne Leidenschaft wirst du die hunderte Stunden Arbeit nicht durchstehen. Nutze Tools wie Zotero zur Literaturverwaltung. Das spart dir Monate an Formatierungsarbeit.
- Definiere deine Suchbegriffe extrem genau. Nutze Synonyme und verschiedene Sprachen.
- Erstelle ein Protokoll und registriere es bei Plattformen wie PROSPERO. Das verhindert, dass andere Forscher gleichzeitig an derselben Fragestellung arbeiten.
- Suche dir einen Partner. Vier Augen sehen immer mehr als zwei. Das minimiert das Risiko für subjektive Fehler bei der Auswahl der Quellen.
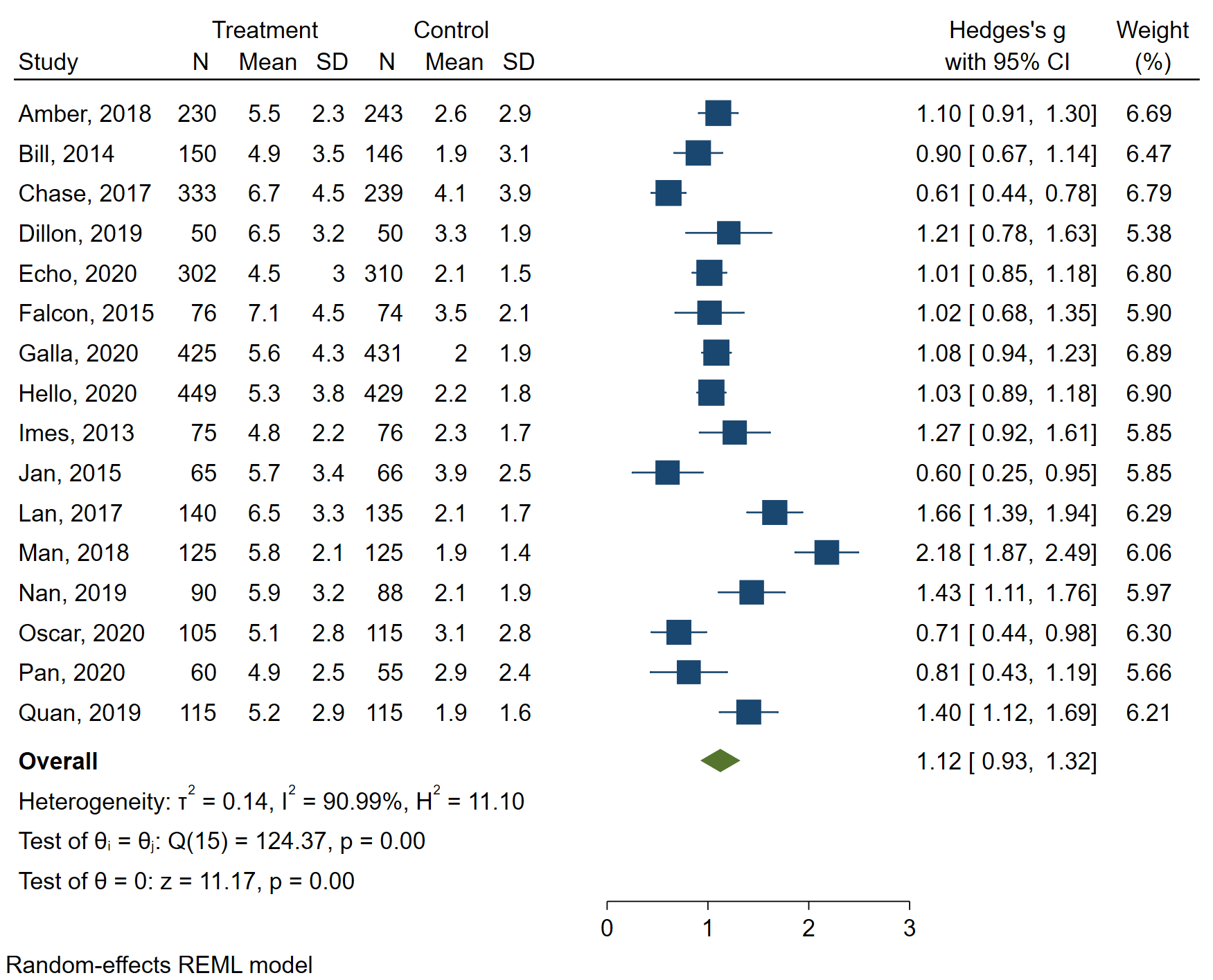
- Lerne die Grundlagen der Statistik. Du musst wissen, was ein Forest Plot ist und wie man die Heterogenität $I^2$ interpretiert. Ohne dieses Wissen bist du verloren.
- Schreibe klar und direkt. Deine Analyse soll gelesen werden, nicht im Regal verstauben. Vermeide unnötiges Fachchinesisch, wo es möglich ist.
Es gibt keine Abkürzung zur Exzellenz. Es ist harte Arbeit. Aber am Ende hast du etwas geschaffen, das Bestand hat. Du hast Ordnung in das Chaos gebracht. Du hast den Menschen eine Orientierungshilfe gegeben in einer Welt, die vor Informationen überquillt. Das ist der wahre Wert einer Meta Analysis Of Meta Analyses.
Nimm dir die Zeit für die Details. Prüfe jede Quelle dreimal. Sei dein härtester Kritiker. Wenn du eine Schwachstelle in deiner Argumentation findest, behebe sie, bevor es jemand anderes tut. Die Wissenschaft lebt vom Diskurs. Sei bereit, deine Position zu verteidigen, aber sei auch bereit, sie zu ändern, wenn die Datenlage es verlangt. Nur so wächst echtes Wissen.
Am Ende des Tages geht es darum, die Qualität der Information zu erhöhen. In Zeiten von Fake News und manipulierten Daten ist eine saubere wissenschaftliche Methodik unser wichtigster Schutzschild. Nutze dieses Werkzeug weise. Es ist mächtiger, als du vielleicht denkst. Fang heute an, die vorhandenen Daten zu ordnen, anstatt nur neue hinzuzufügen. Das ist der Weg zum Expertenstatus. Viel Erfolg bei deiner Suche nach der Wahrheit im Datendschungel.



