Wer große Datenmengen verarbeitet, steht früher oder später vor einem Problem, das den eigenen Rechner komplett lahmlegen kann: der Arbeitsspeicher läuft voll. Stell dir vor, du hast eine Log-Datei mit mehreren Gigabyte Umfang und versuchst, diese einfach stumpf in den Speicher zu laden. Dein System wird innerhalb von Sekunden in die Knie gehen, die Maus ruckelt, und am Ende schmiert dein Skript mit einem Memory Error ab. Genau hier kommt das Konzept Read Python File Line By Line ins Spiel, denn es ist die einzige vernünftige Methode, um mit massiven Textdateien effizient umzugehen, ohne die Hardware zu grillen. Ich habe in den letzten Jahren unzählige Skripte gesehen, bei denen Entwickler aus Bequemlichkeit readlines() verwendet haben, nur um dann mitten in der Nacht von einem Server-Alarm geweckt zu werden.
Es geht nicht nur darum, Code zum Laufen zu bringen. Es geht darum, Code zu schreiben, der auch unter Last stabil bleibt. Wenn wir Daten zeilenweise verarbeiten, nutzen wir die Iteratoren von Python. Das schont die Ressourcen. Ein Iterator lädt immer nur das in den RAM, was gerade wirklich gebraucht wird. Der Rest der Datei wartet geduldig auf der Festplatte. Das ist simpel. Das ist effektiv. Und doch machen es viele falsch.
Das Fundament für Read Python File Line By Line in der Praxis
Der klassische Weg führt über den with-Kontext-Manager. Warum? Weil man früher oder später vergisst, eine Datei manuell zu schließen. Ein offenes Dateihandle ist wie ein tropfender Wasserhahn. Irgendwann ist der Keller voll. Der with-Block sorgt dafür, dass Python aufräumt, egal ob dein Code sauber durchläuft oder mit einer Exception gegen die Wand fährt.
Warum der Kontext-Manager dein bester Freund ist
Ich erinnere mich an ein Projekt bei einem mittelständischen Logistikunternehmen in München. Die Kollegen dort hatten ein Skript, das alle zehn Minuten Statusberichte einlas. Nach drei Tagen stürzte der Server ab. Der Grund war simpel: Jedes Mal wurde die Datei geöffnet, aber bei einem spezifischen Formatfehler wurde der close()-Befehl übersprungen. Das Betriebssystem verweigerte irgendwann neue Dateizugriffe. Mit dem with-Statement wäre das nie passiert. Es ist der Goldstandard der Dateiverarbeitung in Python.
Die Syntax im Detail
Man nutzt heute fast ausschließlich den Iterator des Dateiobjekts selbst. Du musst nicht explizit eine Methode aufrufen, um über die Zeilen zu loopen. Python versteht von sich aus, dass eine geöffnete Textdatei zeilenweise durchlaufen werden soll, wenn man sie in eine for-Schleife steckt. Das ist elegant. Das spart Tipparbeit.
Effiziente Wege für Read Python File Line By Line
Es gibt verschiedene Szenarien, in denen man Daten ausliest. Manchmal ist die Datei winzig, manchmal gigantisch. Manchmal brauchen wir nur bestimmte Informationen aus der Mitte. Hier zeigt sich die Flexibilität der Sprache.
Die einfache Iteration mit der For-Schleife
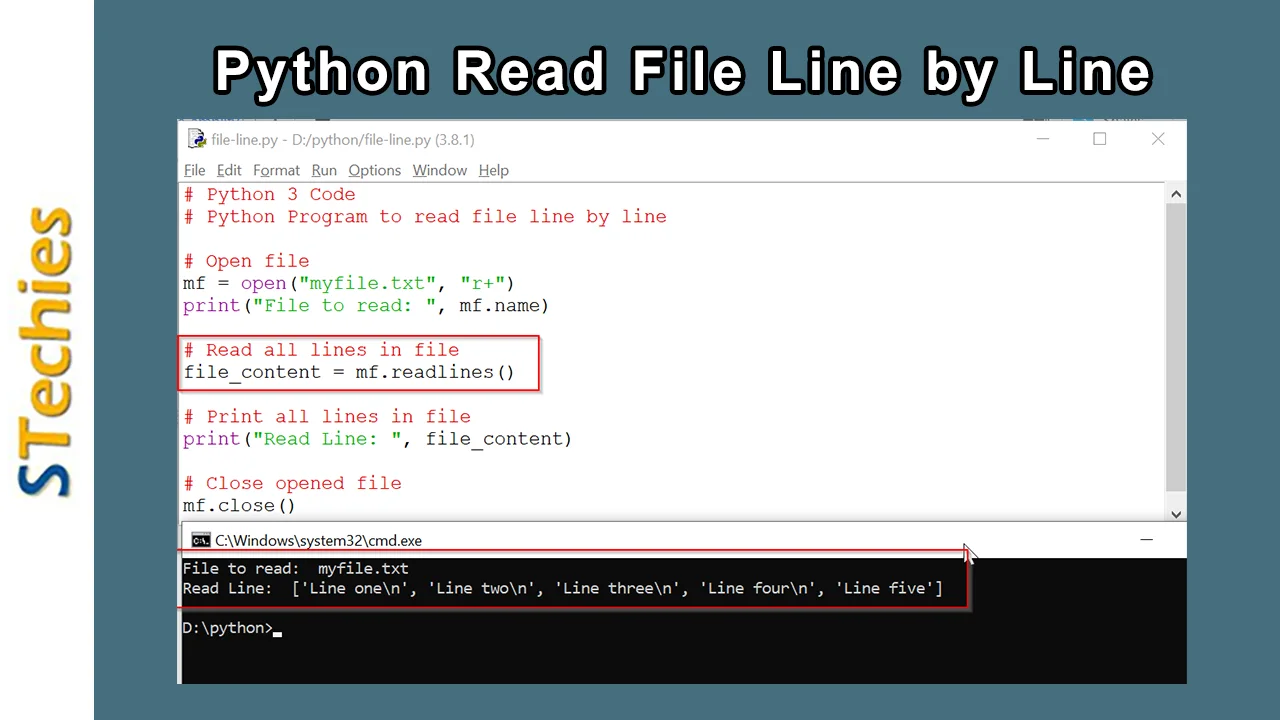
Der direkteste Weg sieht so aus: Du öffnest die Datei im Lesemodus. Dann startest du die Schleife. Jede Zeile landet als String in deiner Variablen. Ein wichtiger Punkt, den Anfänger oft übersehen, ist das Zeilenumbruchzeichen am Ende. Python lässt das \n einfach stehen. Wenn du das nicht entfernst, wunderst du dich später über seltsame Leerzeilen in deiner Ausgabe oder Fehler beim String-Vergleich. Die Methode strip() ist hier dein Werkzeug der Wahl.
Performance-Vorteile durch Generatoren
Wenn du die Daten nicht nur auslesen, sondern transformieren willst, solltest du über Generatoren nachdenken. Ein Generator ist eine Funktion, die Werte mit yield zurückgibt. Das Schöne daran ist, dass die Logik der Verarbeitung von der Logik des Lesens getrennt wird. Das macht deinen Code modular. Du kannst eine Funktion schreiben, die nur für das Filtern zuständig ist, und eine andere, die die Berechnungen anstellt. Alles geschieht weiterhin zeilenweise. Der Speicherverbrauch bleibt flach wie eine Flunder.
Probleme mit der Zeichenkodierung lösen
Ein Thema, das regelmäßig für graue Haare sorgt, ist das Encoding. Wir leben in einer Welt, die glücklicherweise meistens UTF-8 spricht. Aber wehe, du erbst ein altes System, das noch mit Latin-1 oder Windows-1252 arbeitet. In Deutschland begegnet uns das oft bei CSV-Exporten aus alten Excel-Versionen oder SAP-Systemen.
Wenn du beim Einlesen Umlaute wie Ä, Ö oder Ü im Text hast und das Encoding falsch setzt, knallt es. Python wirft einen UnicodeDecodeError. Mein Rat: Gib beim Öffnen der Datei immer explizit encoding='utf-8' an. Falls das nicht klappt, musst du herausfinden, was die Quelle geliefert hat. Tools wie chardet können helfen, aber meistens reicht ein kurzer Blick in die Dokumentation der Datenquelle. Verlasse dich niemals auf das Standard-Encoding des Betriebssystems. Das ist auf einem Linux-Server anders als auf einem lokalen Windows-Rechner.
Umgang mit Fehlern beim Einlesen
Was passiert, wenn eine Zeile korrupt ist? In einer perfekten Welt sind alle Daten sauber. In der Realität gibt es Dateifehler, plötzliche Verbindungsabbrüche bei Netzwerk-Mounts oder einfach Müll im Text. Du kannst das errors-Argument in der open()-Funktion nutzen. Mit errors='ignore' werden problematische Zeichen einfach übersprungen. Mit errors='replace' wird ein Ersatzzeichen eingefügt. Das ist oft besser, als das gesamte Programm sterben zu lassen, nur weil an Position 450.000 ein seltsames Byte steht.
Fortgeschrittene Techniken für riesige Datensätze
Wenn wir über wirklich große Dateien reden, etwa Terabyte an Log-Daten von Cloud-Plattformen, reicht die einfache Schleife manchmal nicht aus. Hier kommen Puffer-Strategien ins Spiel. Python puffert standardmäßig schon recht ordentlich. Aber du kannst die Puffergröße manuell anpassen, um die Anzahl der Systemaufrufe zu minimieren. Das kann bei langsamen Festplatten oder Netzwerkfreigaben einen spürbaren Unterschied machen.
Das Modul linecache für gezielte Zugriffe
Manchmal musst du nicht alles lesen. Manchmal willst du nur Zeile 502, 10.000 und 1.000.000. Python bietet dafür das Modul linecache. Es ist darauf optimiert, zufällige Zugriffe auf Zeilen zu ermöglichen. Der Trick dabei ist, dass das Modul die Datei im Hintergrund clever verwaltet. Das ist extrem nützlich, wenn du Fehlermeldungen aus einem Stacktrace anzeigen willst, ohne die ganze Quelldatei jedes Mal neu zu scannen.
Arbeiten mit Binärdateien
Nicht alles ist Text. Wenn du Binärdaten verarbeitest, die keine klassischen Zeilenumbrüche haben, wird es komplizierter. Hier liest man meistens in festen Blockgrößen, zum Beispiel 4096 Bytes. Das entspricht oft der Blockgröße des Dateisystems auf modernen SSDs. So holst du das Maximum an Geschwindigkeit heraus. Du musst dann im Code selbst entscheiden, wie du die Fragmente wieder zusammensetzt.
Praktische Anwendungsfälle aus der IT-Welt
Nehmen wir an, du arbeitest für einen E-Commerce-Riesen. Du hast eine CSV-Datei mit Millionen von Transaktionen. Du sollst den Gesamtumsatz berechnen. Wenn du die ganze Datei lädst, braucht dein Skript vielleicht 8 GB RAM. Wenn du sie zeilenweise liest, braucht es 20 MB. Der Unterschied ist gewaltig. Es ermöglicht dir, solche Aufgaben auf einer kleinen Lambda-Instanz in der Cloud oder einem günstigen Raspberry Pi zu erledigen, statt teure High-Memory-Server zu mieten.
Log-Analyse in Echtzeit
Ein weiteres Beispiel ist die Überwachung von Server-Logs. Du willst benachrichtigt werden, wenn das Wort "CRITICAL" auftaucht. Hier nutzt man oft eine Endlosschleife, die am Ende der Datei wartet (ähnlich wie der Befehl tail -f unter Linux). Du liest die Datei, verarbeitest die Zeile, und wenn du am Ende ankommst, pausiert das Skript kurz und schaut dann wieder nach, ob neue Zeilen hinzugefügt wurden. Das ist die Basis für viele Monitoring-Tools.
Datenbereinigung und Transformation
Oft müssen Daten für Datenbanken vorbereitet werden. Man liest eine Zeile, prüft die Validität der E-Mail-Adresse, wandelt das Datum in ein ISO-Format um und schreibt das Ergebnis in eine neue Datei oder direkt in eine SQL-Datenbank. Dieser ETL-Prozess (Extract, Transform, Load) profitiert massiv von der zeilenweisen Verarbeitung, da man so auch Dateien bearbeiten kann, die größer sind als der verfügbare Arbeitsspeicher.
Die Performance-Falle: Wann es langsam wird
Obwohl das zeilenweise Lesen speichereffizient ist, kann es bei sehr vielen kleinen Operationen langsam werden. Jede Zeile erfordert einen Durchlauf der Schleife und diverse Funktionsaufrufe. Wenn du innerhalb der Schleife komplexe Regex-Muster anwendest, summiert sich die Zeit.
In solchen Fällen kann es helfen, die Daten in größeren Blöcken zu lesen und diese Blöcke im Speicher aufzuteilen. Aber Vorsicht: Das erhöht die Komplexität deines Codes erheblich. Meistens ist die einfache Iteration schnell genug. Optimierung sollte man nur betreiben, wenn man durch Messungen bewiesen hat, dass der aktuelle Weg zu langsam ist. Nutze dafür das Modul timeit oder Profiler wie cProfile.
Sicherheit beim Umgang mit Dateien
Ein oft unterschätzter Aspekt ist die Sicherheit. Wenn der Pfad zur Datei von einem Benutzer eingegeben werden kann, öffnest du Tür und Tor für Angriffe. Stichwort: Path Traversal. Ein Angreifer könnte versuchen, über Sequenzen wie ../../etc/passwd sensible Systemdateien auszulesen.
Validierung ist hier Pflicht. Nutze die moderne pathlib-Bibliothek von Python. Sie ist deutlich intuitiver als das alte os.path. Mit pathlib.Path kannst du Pfade sicher zusammenbauen und prüfen, ob sie innerhalb eines erlaubten Verzeichnisses liegen. Das schützt deine Anwendung davor, ungewollt Geheimnisse preiszugeben.
Dateiberechtigungen beachten
Gerade in einer Linux-Umgebung musst du sicherstellen, dass dein Skript die nötigen Rechte hat. Wenn ein Cronjob unter einem eingeschränkten Benutzer läuft, scheitert der Zugriff oft kläglich. Prüfe vorher mit os.access(), ob die Datei lesbar ist, bevor du versuchst, sie zu öffnen. Das gibt dir die Chance, eine saubere Fehlermeldung auszugeben, statt das Programm mit einem Traceback abstürzen zu lassen.
Alternative Bibliotheken für Spezialfälle
Wenn deine Dateien strukturierter sind als normaler Text, gibt es bessere Werkzeuge als die Standardfunktionen. Für CSV-Dateien ist das integrierte csv-Modul hervorragend. Es kümmert sich um Quotings und Delimiter, die dir bei einem einfachen split(',') um die Ohren fliegen würden.
Für wissenschaftliche Daten oder sehr große Tabellen ist Pandas oft die erste Wahl. Aber Vorsicht: Pandas ist hungrig nach Arbeitsspeicher. Wenn du eine 10 GB Datei mit pd.read_csv() lädst, ist dein RAM sofort weg. Glücklicherweise bietet Pandas den Parameter chunksize. Damit kannst du die Datei in Häppchen lesen, was im Grunde eine High-Level-Variante der zeilenweisen Verarbeitung ist. Du bekommst dann in jedem Schleifendurchlauf einen DataFrame statt eines Strings. Das kombiniert die Bequemlichkeit von Pandas mit der Effizienz der Iteration.
Warum wir Python für diese Aufgaben lieben
Python macht es uns verdammt einfach. In anderen Sprachen wie C oder Java musst du dich oft mit komplexen Buffern, File-Descriptoren und Low-Level-APIs herumschlagen. In Python sind es drei bis vier Zeilen Code. Diese Abstraktion ist Gold wert, solange man versteht, was unter der Haube passiert.
Die Community hat über Jahrzehnte dafür gesorgt, dass die Datei-I/O-Operationen hochgradig optimiert sind. Die meiste Zeit verbringt das Skript damit, auf die Hardware zu warten (I/O Bound). Python selbst ist hier selten der Flaschenhals. Wenn du Geschwindigkeit willst, achte auf schnelle SSDs und ein effizientes Dateisystem wie ext4 oder APFS.
Die Rolle von Hardware und Betriebssystem
Es macht einen Unterschied, ob dein Skript auf einem Windows-Laptop oder einem Debian-Server in einem Rechenzentrum läuft. Windows verwendet standardmäßig andere Zeilenenden (\r\n) als Unix-Systeme (\n). Python ist klug genug, das im Textmodus automatisch zu handhaben. Das nennt sich "Universal Newlines Support".
Wenn du jedoch Dateien zwischen Systemen hin- und herkopierst, kann es manchmal zu Verwirrung kommen. Vor allem, wenn Git-Einstellungen die Zeilenenden beim Checkout verändern. Sei dir dessen bewusst, wenn deine Zeilenlängen plötzlich nicht mehr stimmen oder seltsame Steuerzeichen am Ende auftauchen.
Caching-Mechanismen verstehen
Moderne Betriebssysteme cachen Dateien, die häufig gelesen werden, im RAM. Wenn du dein Skript zweimal hintereinander ausführst, ist der zweite Durchlauf oft viel schneller. Das liegt nicht an deinem Code, sondern am Page Cache des Kernels. Wenn du die wahre Performance deines Skripts messen willst, musst du die Caches leeren, was auf Produktivsystemen oft gar nicht so einfach ist.
Was wir aus der Geschichte lernen können
Früher war Speicher teuer. Programmierer in den 70ern und 80ern hatten gar keine andere Wahl, als alles zeilenweise oder blockweise zu verarbeiten. Dann kam eine Ära, in der RAM im Überfluss vorhanden schien, und viele wurden schlampig. Heute, im Zeitalter von Big Data und Cloud Computing, kehren wir zu diesen Tugenden zurück. Effizienz ist wieder ein Wettbewerbsvorteil. Ein Skript, das auf einer 1-Kern-Maschine mit 512 MB RAM läuft, kostet in der Cloud nur einen Bruchteil einer riesigen Instanz.
Die Bedeutung von sauberem Code
Code wird öfter gelesen als geschrieben. Ein sauberer with-Block mit einer klaren for-Schleife ist für jeden Entwickler sofort verständlich. Vermeide kryptische Einzeiler oder komplexe List-Comprehensions beim Dateilesen, wenn die Logik darin zu kompliziert wird. Lesbarkeit ist wichtiger als die Ersparnis von zwei Zeilen Code.
Praktische Schritte zur Umsetzung
Damit du das Gelernte direkt anwenden kannst, hier ein konkreter Schlachtplan für dein nächstes Projekt.
- Analysiere die Datenquelle: Wie groß ist die Datei wirklich? Welches Encoding wird verwendet? Gibt es Besonderheiten bei den Zeilenenden?
- Wähle die richtige Methode: Für einfachen Text ist die Standard-Iteration perfekt. Für CSV nimm das
csv-Modul. Für massive Tabellen nutze Pandas mitchunksize. - Implementiere Fehlerbehandlung: Nutze
try-except-Blöcke, um auf fehlende Dateien oder Berechtigungsprobleme zu reagieren. - Entferne unnötigen Ballast: Nutze
strip()oderrstrip(), um Zeilenumbrüche und Leerzeichen an den Rändern loszuwerden. - Teste mit realistischen Daten: Probiere dein Skript nicht nur mit einer 10-Zeilen-Testdatei aus. Nimm eine Kopie der echten Daten, um die Performance unter realen Bedingungen zu sehen.
- Dokumentiere Annahmen: Schreibe kurz in den Kommentar, warum du dich für ein bestimmtes Encoding oder eine bestimmte Puffergröße entschieden hast. Dein zukünftiges Ich wird es dir danken.
Die Arbeit mit Dateien gehört zum täglich Brot eines Programmierers. Wer hier die Grundlagen beherrscht, baut stabilere und schnellere Systeme. Es ist kein Hexenwerk, aber es erfordert Sorgfalt. Wenn du das nächste Mal vor einer riesigen Log-Datei stehst, weißt du jetzt genau, wie du sie bändigst, ohne dass dein Rechner um Hilfe schreit.
Falls du dich tiefer in die Materie einarbeiten willst, schau dir die offizielle Python-Dokumentation zu I/O an. Dort findest du alle Details zu den verschiedenen Streams und Puffern. Es lohnt sich, diese Konzepte einmal richtig zu durchdringen, statt nur Code-Schnipsel von Stack Overflow zu kopieren. Am Ende macht das den Unterschied zwischen einem Bastler und einem echten Profi aus. Wer weiß, vielleicht entdeckst du dabei sogar Optimierungen, an die bisher noch niemand gedacht hat. Programmierung ist schließlich auch ein Handwerk, das man durch ständiges Verfeinern der Techniken meistert. Jede Zeile Code, die du heute besser schreibst, spart dir morgen Zeit bei der Fehlersuche. Und Zeit ist in unserer Branche bekanntlich die wertvollste Ressource.



